Si eres administrador de plataformas de e-learning, director de una escuela, administrador de sistemas o profesor, seguramente te habrás preguntado en alguna ocasión cuántos usuarios soporta Moodle. No hay una respuesta simple o sencilla para ello ya que depende de varios factores por lo que en este artículo, te ayudaré a tener una mayor comprensión del tema para que evalúes y elijas correctamente lo que se ajuste a tu presupuesto.
Tabla de contenidos
Servidores y Servidores Web
Un servidor, tradicionalmente definido, es un equipo de cómputo conectado a una red de computadoras, con software configurado para tal propósito que tiene la capacidad de atender o dar respuesta a todas y cada una de las peticiones que recibe a través de la misma, según las especificaciones o protocolo utilizado y configurado para ello.

Por ejemplo, cuando Tim Berners Lee creó las especificaciones del protocolo HTTP para dar paso a la World Wide Web, configuró una computadora NeXT para desplegar y servir páginas web o “de hipertexto” a sus compañeros científicos en el CERN de Suiza, algo novedoso y completamente revolucionario.
En este sentido, el puerto asignado al protocolo HTTP fue el puerto 80. No obstante lo anterior, previo a esto, ya existía el puerto 20 para conexiones mediante consola a través de Telnet, puerto 21 para transferencia de archivos mediante FTP, puerto 22 para conexiones cifradas mediante consola mediante SSH, puerto 25 para correo electrónico y así sucesivamente. Para que un servidor o equipo de cómputo permitiese la conexión a estos puertos en una red, era necesario configurar en dicho equipo cada uno de ellos mediante programas que se ejecutan en memoria como “servicios”.
Así, en nuestra comprensión de qué es un “servidor”, podemos decir que cada puerto o protocolo tiene como misión y propósito proveer un “servicio” o conjunto de “servicios” a nuestros “clientes” según el protocolo que utilice. Así, un servidor web, puede ser entendido como un programa (el servidor web más popular es Apache seguido de Nginx mediante el puerto 80 (HTTP) o puerto 443 (HTTPS), el cual provee a nuestros usuarios del acceso a páginas web planas o de hipertexto (HTML) o bien, páginas generadas a través de procesadores de páginas de hipertexto como PHP, Phyton, etc.
Si un cliente (usuario, visitante, cibernauta, etc.) realiza una petición a nuestro servidor, de manera técnica lo que podemos decir es que solicita una respuesta a un servicio previamente configurado (servidor web Apache o servidor web Nginx) que está funcionando en ese momento en memoria para responder y dar respuesta a ello.
Con esto en consideración, y gracias a la generosidad de los entusiastas del software libre, hoy en día un servidor web puede cubrir múltiples funciones y satisfacer múltiples demandas.
¿Qué recursos necesito para implementar un servidor web?
Por ello, es importante mencionar que para que un sitio web complejo pueda funcionar basado en GNU/Linux, Apache, PHP y MySQL o MaríaDB (un servidor LAMP), a grandes rasgos, necesitarás de:
- Un servidor físico o virtual con conexión a Internet, espacio en disco duro suficiente, memoria RAM y otros recursos de misión crítica como procesador, sistema operativo, etc.
- Una dirección IP pública estática (o dinámica, más complejo de usar, pero no imposible de configurar) para tu servidor físico o virtual.
- Un software que actúe como servicio de servidor web como Apache o Nginx para el procesamiento e interpretación de páginas HTML mediante el protocolo HTTP.
- Un procesador o intérprete como PHP que facilite la generación dinámica de páginas de hipertexto.
- Un servicio que actúe como servidor de base de datos como MariaDB, PostgreSQL o MySQL.
Adicionalmente, si quieres tener URLs amigables para tu sitio web, requerirás de:
- Un nombre de dominio contratado del tipo misitioweb.com.
- Un servidor DNS que redireccione tu dominio contratado a la dirección IP pública estática (o dinámica) de tu servidor física o virtual.
Todo esto, en conjunto, requiere de una adecuada instalación instalación y configuración de paquetes y librerías que permitan optimizar y garantizar la disponibilidad de tus servicios, así como una correcta resolución de peticiones de los clientes, usuarios o visitantes de tu sitio web.

Con todo, ¿cuántos usuarios soporta Moodle?
En este punto, vamos a resolver tu duda y tratar de responder lo más objetivamente: antes de preguntarte cuántos usuarios soporta Moodle, debes tratar de encuadrar y definir primero tu problemática o escenario deseado en los siguientes términos:
- ¿Qué experiencia de usuario deseas brindar a tus alumnos y profesores?
- ¿Cuántos usuarios en total tienes programado atender?
- ¿Cuántos de estos usuarios serán concurrentes o se conectarán simultáneamente? ¿En qué momentos podrías tener alta demanda que derive en cuellos de botella?
- ¿Qué tanta tolerancia tendrías a respuestas lentas del servidor en horas pico?
- ¿Cuáles son tus perspectivas de crecimiento en el corto, mediano y largo plazo?
Con lo anterior en consideración, te daré un dato: Moodle es un LMS (Learning Management System) súmamente robusto que ofrece una gran cantidad de recursos para diseñar y programar nuestros cursos. Para que te des una idea, el código fuente o paquete comprimido de la versión de Moodle 4.2+, tiene un tamaño de archivo de 62.2 MB en formato tar.gz. Estos datos son determinantes para calcular cuántos usuarios soporta Moodle.
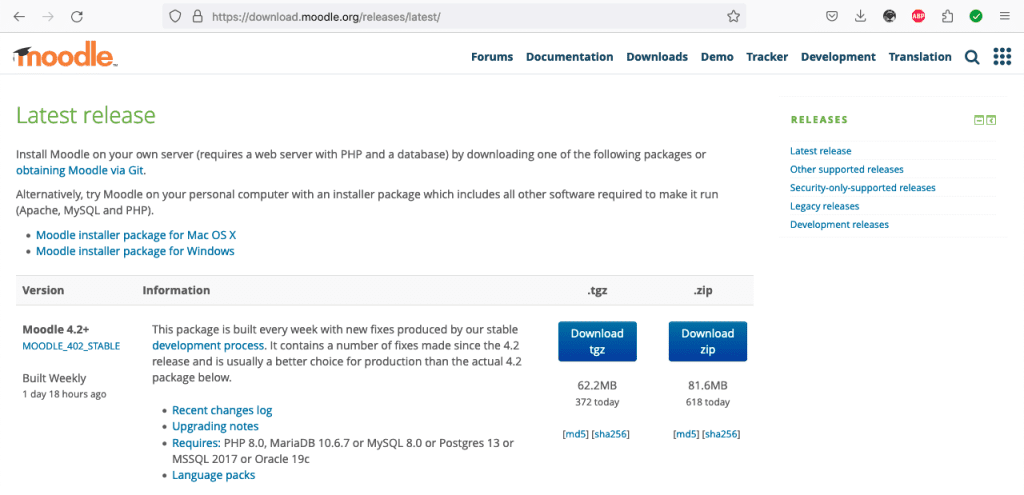
Ello no quiere decir que esos recursos ya descomprimidos estarán simultáneamente procesándose completa y enteramente en la memoria RAM del servidor; sin embargo, es un dato de referencia que no debemos perder de vista.
Con ello, más o menos desde la versión 1.x de Moodle, surgió una recomendación sobre la cantidad de memoria RAM que debe tener un servidor web para atender N número de usuarios: por cada 10 – 20 usuarios concurrentes, se recomienda tener disponibles 1 GB de memoria RAM.
A grandes rasgos, si tienes una escuela con 100 alumnos y esperas que los 100 se conecten al mismo tiempo (concurrencia), deberías de tener 5 GB de memoria RAM + unos 2 o 4 GB adicionales para al sistema operativo de tu servidor web Apache o Ngix.
Ahora bien, es probable que tus usuarios no estarán conectados las 24 hrs. del día de manera concurrente o simultánea sino que existan “eventos” más o menos “dispersos” a lo largo del tiempo por lo que, a manera de “riesgo calculado” podrías decidir decir: voy a destinar 2 GB de memoria RAM para Moodle + 2 GB para mi sistema operativo con los cuales atenderé a 100 usuarios en total, pero entiendo y comprendo que 40 usuarios concurrentes están garantizados.
Este es un escenario o panorama con riesgos calculados y tolerados.
¿Cuál es el escenario que te resulta ideal? ¿Qué tanta tolerancia tienes a probables demoras, fallos o errores?
En ambientes GNU/Linux, existen múltiples formas, si no tienes memoria RAM física pero sí un disco duro de estado sólido, para conseguir “memoria” adicional pero eso, será motivo de otro artículo.
Calcular el número de usuarios que soporta Moodle
Te dejo aquí un par de calculadoras en línea que he elaborado para que pueda obtener un estimado de:
- Cantidad de usuarios concurrentes en Moodle que soporta un servidor web en función de la cantidad de memoria RAM disponible.
- Cantidad de memoria RAM que necesitas para atender a N número de usuarios de Moodle de manera concurrente.
¡Utiliza las barras de desplazamiento!
Conclusiones
Como has podido observar, el performance o desempeño esperado de un servidor web y, sobre todo, de una instalación de Moodle, depende de una gran cantidad de factores como la cantidad de dinero que estás dispuesto a invertir en los recursos necesarios de servidor (memoria, disco, ancho de banda), riesgos tolerados, concurrencia de usuarios estimada, etc.
Ahora bien, cada instalación de Moodle es distinta así como el comportamiento de los usuarios.
Generalmente la concurrencia de usuarios suele darse en periodos de exámenes, por ejemplo, en las noches (un hábito que he observado sobre las nuevas generaciones o personas que trabajan en mi experiencia), etc.
Por lo anterior, en casi la totalidad de casos no es necesario destinar y garantizar el 100% de cumplimiento en recursos del servidor. Al final del día, la decisión es tuya; tú decides cuánto estás dispuesto a invertir y determinar qué calidad en la experiencia de usuario deseas brindar a tus usuarios.
Si deseas profundizar más sobre el tema, te recomiendo los siguientes artículos de Moodle:
- User site capacities: https://docs.moodle.org/19/en/User_site_capacities
- Performance FAQ: https://docs.moodle.org/402/en/Performance_FAQ
Encender el ventilador de una laptop Acer Predator Helios 300 PH315-51 en Linux
La línea Predator de computadoras tipo laptop de Acer, incorporan un software llamado PredatorSense a través del cual, como usuarios, podemos controlar el encendido o apagado (manual o automático) de nuestra computadora. Desafortunadamente, PredatorSense solo funciona en Windows por lo que, aquellos usuarios que utilizamos sistemas operativos alternativos basados en GNU/Linux, no podemos disponer de una herramiento oficial para ello. Por ello, en esta ocasión, echaremos mano de algunos hacks y utilidades que he encontrado por ahi para conseguir encender el ventilador de una laptop Acer Predator Helios 300 PH315-51 en Linux. ¡Veamos!
PredatorSense para Windows
Como te lo comentaba al inicio del post, PredatorSense no tiene otra función más que la de controlar el ventilador de tu computadora de manera manual o automática y en distintos grados de intensidad.
Si realizas una instalación limpia de Windows y borraste por alguna razón la partición de drivers y utilidades de tu PC, es recomendable que descargues e instales esta herramienta. El link del sitio es: https://www.acer.com/ac/es/ES/content/predatorsense; no obstante, descárgala directamente desde la sección de utilidades al realizar una búsqueda de drivers para tu modelo específico de computadora.
Encender el ventilador de una laptop Acer Predator Helios 300 PH315-51 en Linux
Bien. Como te comentaba: no existe una herramienta oficial de Acer para hacer funcionar los ventiladores o fans de nuestra laptop en GNU/Linux, lo cual es decepcionante. Para serte franco, y desde mi punto de vista, los fabricantes tendrían que ofrecer las herramientas y detalles técnicos mínimos para aprovechar las funciones de nuestros equipos sin importar su sistema operativo (que al día de hoy, bien puede ser GNU/Linux, Windows e, inclusive, Android) de nuestra PC.
Sin embargo, siempre hay buenos samaritanos que buscan explorar y explotar al máximo el poder del pingüino por lo que, gracias a un hack, es posible tener cuando menos la función de “encender” o “apagar” nuestro ventilador con el uso de herramientas externas.
NBFC (NoteBook Fan Control) para Linux
NBFC es una herramienta multiplataforma que es capaz de ajustar configuraciones específicas para controlar los ventiladores de distintos modelos de computadora.
El link oficial del proyecto es: https://github.com/hirschmann/nbfc
Primeros pasos: instalar NBFC en Linux
Para el desarrollo de este tutorial, estaré trabajando bajo GNU/Linux Ubuntu 22.04 por lo que, algunos de los comandos que veas por aquí, tendrás que adaptarlos si es que usas distribuciones distintas o alternativas. No obstante, no creo que tengas mayores problemas.
En primer lugar, vamos a instalar el conjunto de herramientas Mono para correr programas compatibles desarrollados en .NET en Linux. Para ello, agregamos el repositorio de Mono a nuestro directorio de fuentes de software, actualizamos el repositorio e instalamos Mono.
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv-keys 3FA7E0328081BFF6A14DA29AA6A19B38D3D831EF
echo "deb https://download.mono-project.com/repo/ubuntu stable-bionic main" | sudo tee /etc/apt/sources.list.d/mono-official-stable.list
sudo apt update && sudo apt upgrade -y
sudo apt install mono-complete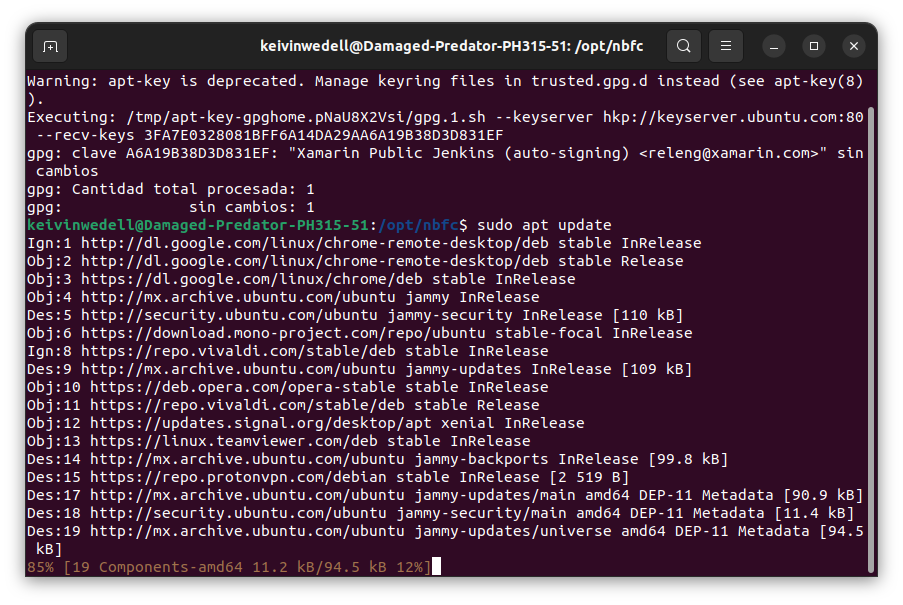
Ahora, como siguiente paso, deberemos instalar Git en nuestra computadora:
sudo apt install gitHecho lo anterior, procederemos a descargar NBFC en nuestro directorio Descargas/nbfc con el siguiente comando:
git clone --depth 1 https://github.com/hirschmann/nbfc.git ~/Descargas/nbfcUna vez hecho lo anterior, procederemos a crear un directorio en /opt/nbfc y, posteriormente, a copiar los archivos que descargamos mediante Git de nuestro directorio ~/Downloads/nbfc.
sudo mkdir /opt/nbfc
sudo cp -r ~/Descargas/nbfc/Linux/bin/Release/* /opt/nbfc/
sudo cp ~/Descargas/nbfc/Linux/{nbfc.service,nbfc-sleep.service} /etc/systemd/system/
cd /opt/nbfcCon esto, ¡ya tienes nbfc disponible en tu computadora!
Encender y apagar ventiladores de Acer Predator Helios 300 PH315-51 en Linux
Ahora, para encender los ventiladores de nuestra laptop Acer Predator Helios 300 PH315-51 en Linux, según el post “Fan control in Linux” de Namangup, solo tenemos que ejecutar dentro del directorio /opt/nbfc el siguiente conjunto de comandos:
sudo modprobe -r ec_sys
sudo modprobe ec_sys write_support=1
sudo mono ec-probe.exe write 0x21 0x64
sudo mono ec-probe.exe write 0x22 0x0cAhora bien, Namangup especifica 2 comandos adicionales en donde 00 es el valor más bajo y 64 el valor más alto para indiciar la intensidad del ventilador dentro de [value].
En este sentido, los comandos en cuestión son:
ec_probe write 0x37 0x[value]
ec_probe write 0x3a 0x[value]En mi experiencia personal, pude encender el ventilador de una laptop Acer Predator Helios 300 PH315-51 en Linux con este comando:
sudo mono ec-probe.exe write 0x21 0x64…y pude apagar el ventilador de una laptop Acer Predator Helios 300 PH315-51 en Linux con este otro:
sudo mono ec-probe.exe write 0x21 0x00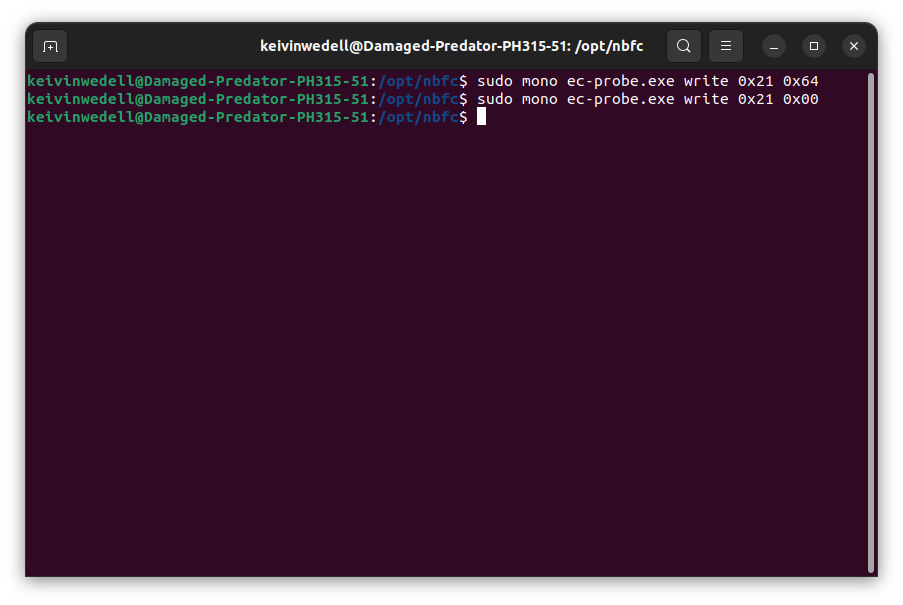
Si estos comandos no te funcionan, es probable que esté funcionando como servicio nbfc por lo que, puedes verificarlo así:
sudo systemctl status nbfc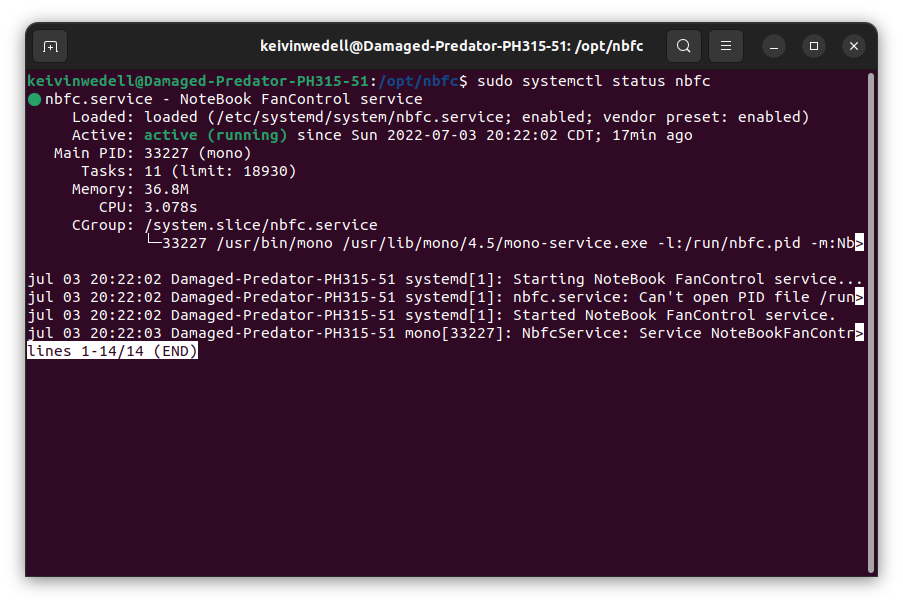
Si el servicio está ejecutándose (running), puedes detenerlo ejecutando el siguiente comando:
sudo systemctl stop nbfc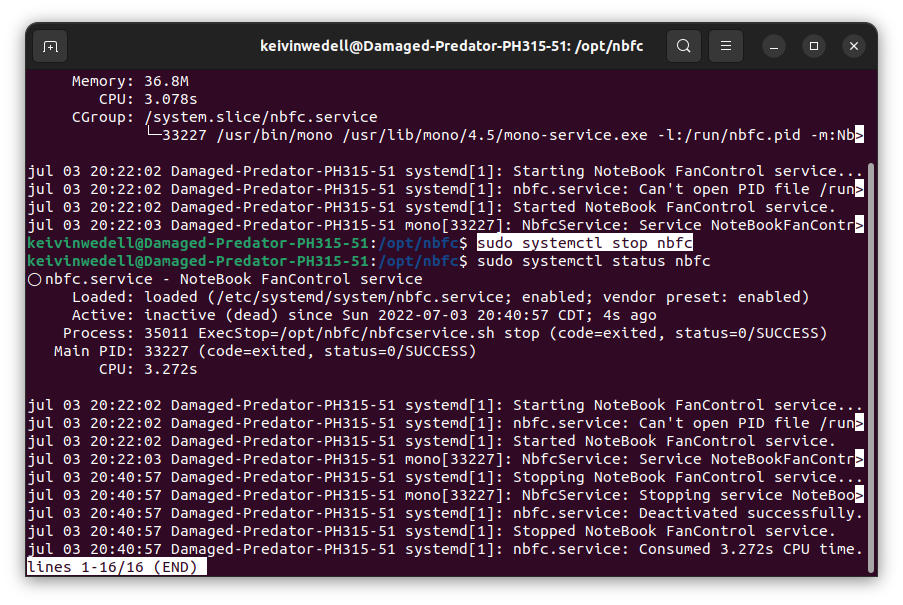
Y vuelve a intentar con los comandos “sudo mono ec-probe.exe write 0x21 0x64” y “sudo mono ec-probe.exe write 0x21 0x00” para encender y apagar los ventiladores.
pIndependientemente de que estos comandos realmente funcionan, para serte honesto, no me fue posible elegir otras intensidades o velocidad de las revoluciones de los ventiladores.
Por ello, exploré más opciones y encontré la posibilidad de utilizar archivos de configuración previamente desarrollados con las opciones disponibles, hallazgos y experimentos personales de diversos desarrolladores y entusiastas.
Utilizar nbfc con opciones preconfiguradas
Como te lo comentaba: debes saber que nbfc viene por defecto con distintas configuraciones preconfiguradas para comenzar a trabajar de inmediato.
Antes de continuar y comenzar a experimentar opciones preconfiguradas, debemos activar nbfc como servicio mediante el siguiente comando:
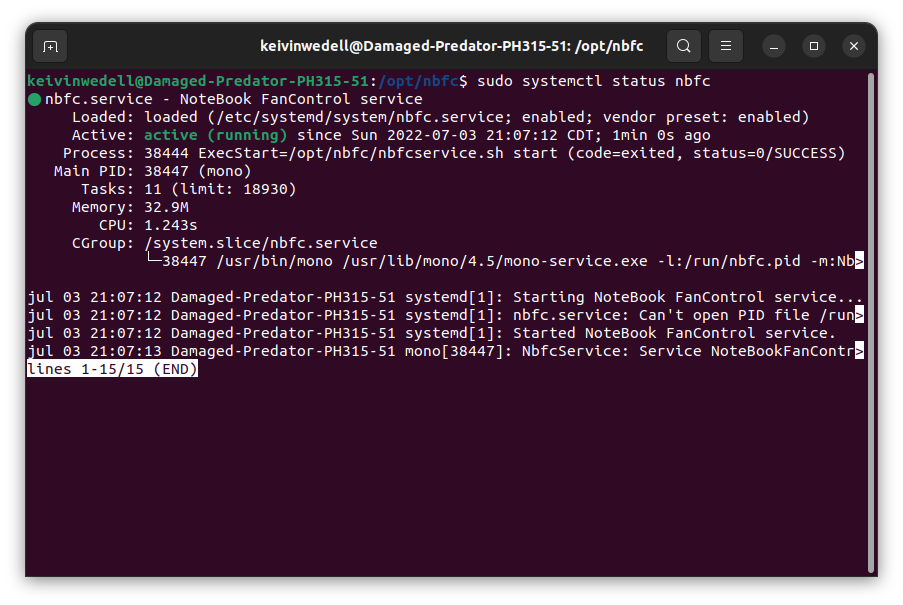
sudo systemctl enable nbfc --nowPara asegurarte de que esté activo lanza una comprobación así:
sudo systemctl status nbfcSi está activo, deberá mostrarse por ahí la palabra “active (running)”.
Hecho lo anterior, la forma más fácil de averiguar qué configuración podría funcionar en tu computadora es que ejecutes dentro del directorio /opt/nbfc el siguiente comando:
sudo mono nbfc.exe config -r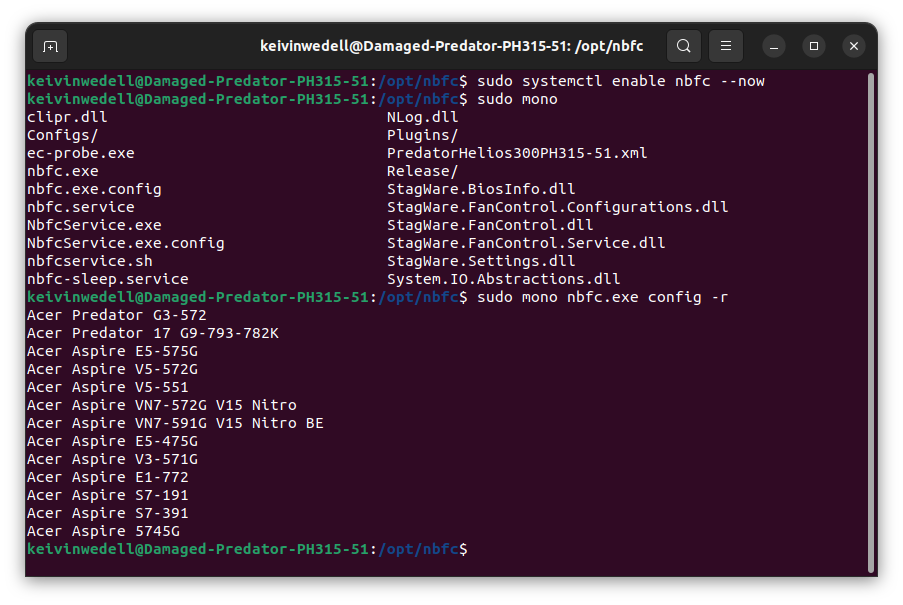
…e inmediatamente se te desplegará una lista recomendaciones de configuraciones prefabricadas para distintos tipos de computadora.
En mi caso, como tengo una computadora Acer Predator Helios 300 PH315-51, la configuración que más se le podría parecer es la de la Acer Predator G3-572 por lo que, para activarla de inmediato, solo debes de ejecutar:
sudo mono nbfc.exe config -a "Acer Predator G3-572"Y sería todo. Con esto, habrás conseguido implementar el servicio de encendido automático del ventilador de tu computadora Acer Predator Helios 300 PH315-51 de manera eficiente y en automático en tu computadora.
Ahora, si así lo deseas, puedes obtener información sobre la configuración actual de nbfc tecleando lo siguiente:
sudo mono nbfc.exe status -a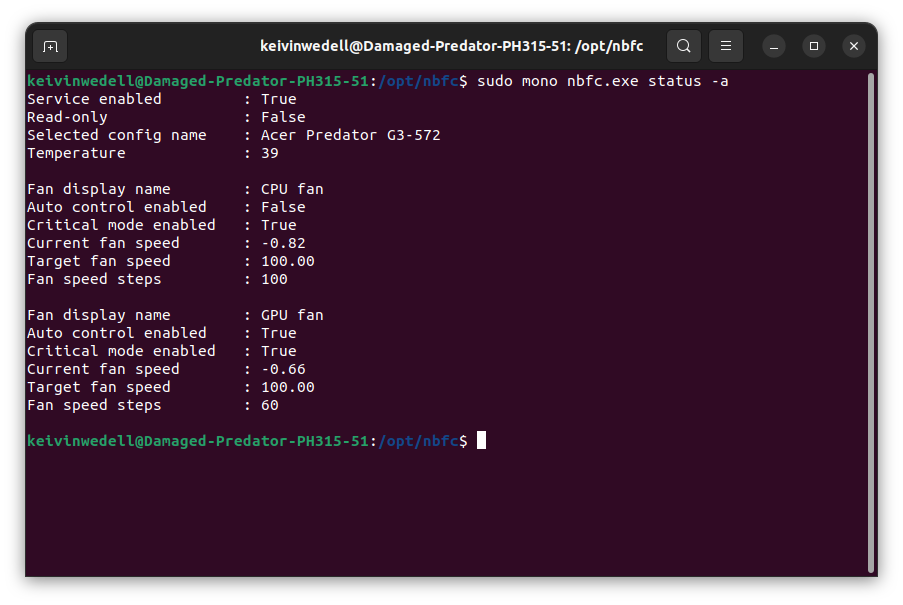
Lo anterior, resulta muy útil ya que así puedes probar distintas configuraciones y experimentar.
Para saber más
- NBFC de Hirschmann en Github: https://github.com/hirschmann/nbfc
- Primeros pasos del tutorial de Hirschmann en Github: https://github.com/hirschmann/nbfc/wiki/First-steps
- Crear archivos de configuración del tutorial de Hirschmann en Github: https://github.com/hirschmann/nbfc/wiki/Create-a-config-file
- Prueba registros EC del tutorial de Hirschmann en Github: https://github.com/hirschmann/nbfc/wiki/Probe-the-EC%27s-registers
- C port of Stefan Hirschmann’s NoteBook FanControl: https://bestofcpp.com/repo/nbfc-linux-nbfc-linux-cpp-miscellaneous
- Cómo controlar la velocidad de los ventiladores de tu laptop: https://linustechtips.com/topic/1107542-how-to-control-your-laptop-fan-speed/
Instalar el software Lenovo Nerve Center
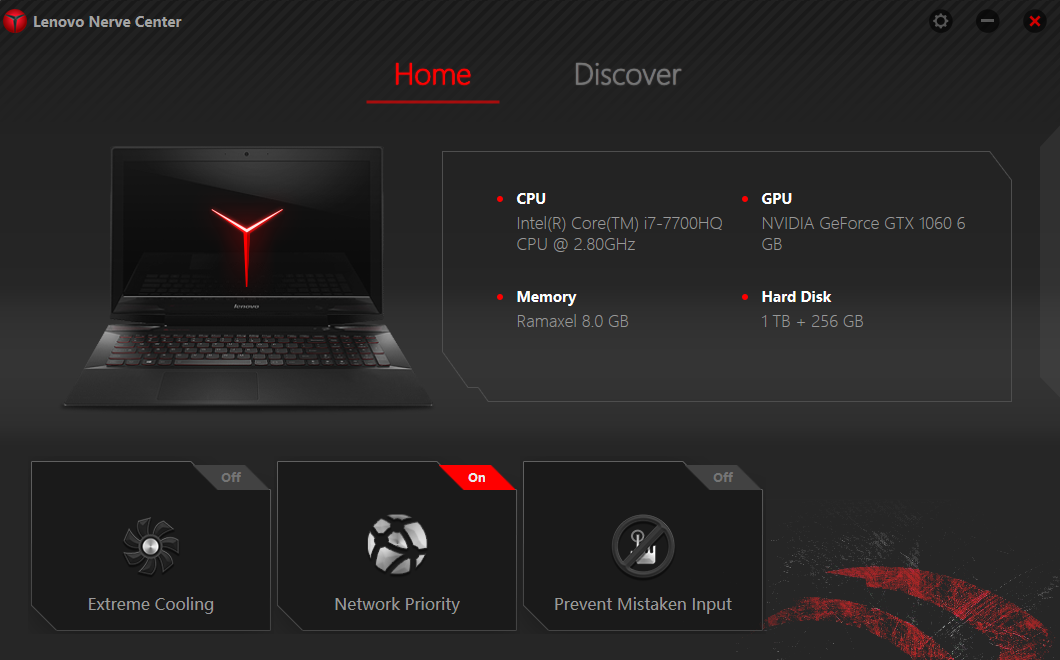
Tuve la necesidad de reinstalar Windows desde cero en mi computadora Lenovo Y720 con lo cual, al instalar los drivers, me pareció extraño no encontrar una herramienta que me resultaba de gran utilidad para “echar a andar” los ventiladores que me permiten refrigerar y mejorar el rendimiento de CPU / tarjeta gráfica a voluntad, y por la cual me era imposible Instalar el software Lenovo Nerve Center que acompañó a mi laptop desde que la compré por ahí del año 2017.
Ya en ocasiones anteriores había notado algunos problemas en este modelo computadora como el de solucionar error en menú contextual en Lenovo Legion Y720 (tap two fingers) que documenté en años pasados en este blog (creo que muy pocos usuarios se han dado cuenta de esto).
Pues bien, el tema es el siguiente: en la base de conocimiento de Lenovo que puedes consultar en https://pcsupport.lenovo.com/th/es/solutions/ht508689-lenovo-common-preloaded-software, comentan que el Lenovo Nerve Center que viene dentro de la lista de software precargado de los equipos Legion Y720-15IKB, ha sido descontinuado o al alcanzado el fin del periodo de vida.
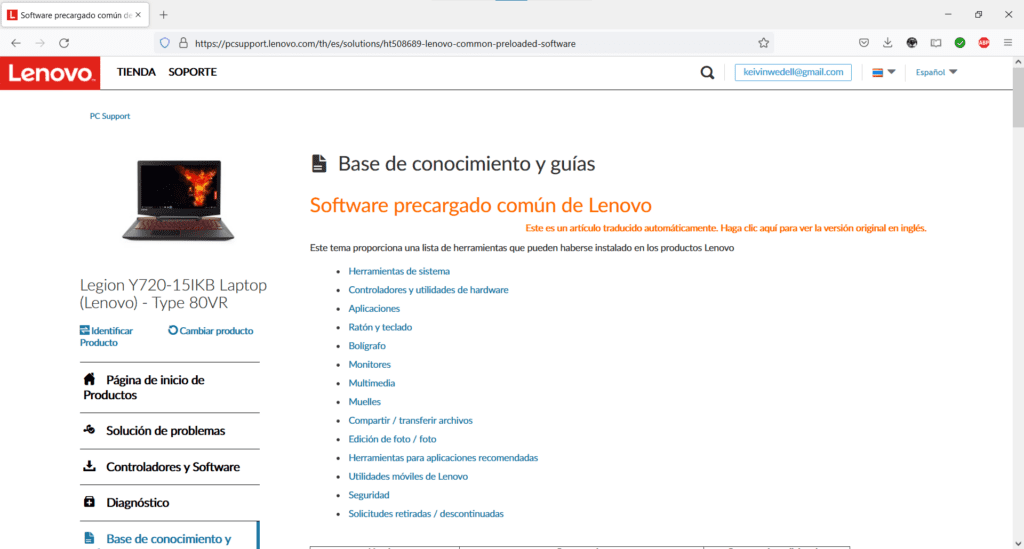

Con ello en consideración, establecí una sesión de chat con un técnico de Lenovo a quien le expuse la situación y el problema para conseguir el Lenovo Nerve Center, el cual dejó de estar disponible tanto para descarga en la página web de Lenovo como en Tienda de Microsoft para su instalación, y lo único que me comentó fue:
- Que software Lenovo Nerve Center ya no estaba disponible.
- Que el Lenovo Nerve Center presentó una vulnerabilidad (no me dijeron cual, ni en qué consistía).
- Que me recomendaba utilizar un software de terceros (bajo mi propia responsabilidad y riesgo).
- Que no saben cómo activar los ventiladores si saldrá una actualización, driver o mejora.
Mi comentario al técnico fue simple: era frustrante y decepcionante que Lenovo decidiera eliminar una característica fundamental (y razón por la cual mucha gente compramos este tipo de equipos, ¡ventilación, refrigeración, rendimiento!) sin ofrecer una alternativa, software sustituto o drivers mejorados u optimizados. Sinceramente, Lenovo nos ha dejado solos. Esto haciendo y documentando lo que Lenovo tendría que informar a sus clientes.
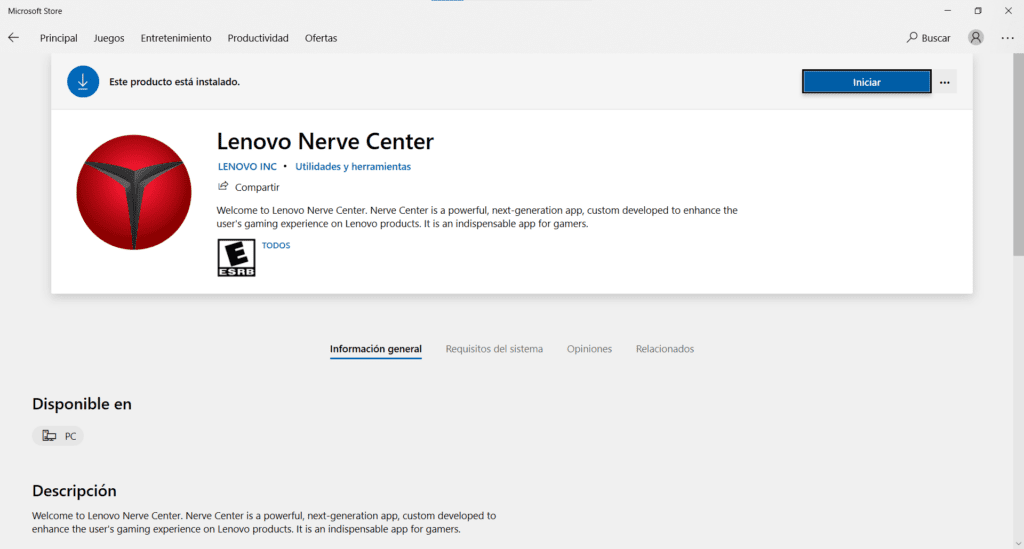
No obstante lo anterior, te comparto un tip y mi experiencia para recuperar y/o volver a instalar el software Lenovo Nerve Center (un poco “forzado” el tema y esperando que Microsoft no retire la app de la Tienda pronto).
¿Cómo instalar el software Lenovo Nerve Center de nuevo en tu laptop?
Los pasos que tienes que seguir son los siguientes:
- Descarga el archivo wwnc02ae.exe que se encuentra en https://download.lenovo.com/consumer/mobiles/wwnc02ae.exe o bien, si por alguna razón dejara de ser provisto por el fabricante, encontré este otro link de respaldo por ahí: https://mega.nz/file/iNggQZKL#kdsMhV65SwvfI2pd5zi2JuniBMND99RGM0c4S0AGWTM.
- Instálalo y reinicia tu equipo.
- Abre el software Lenovo Nerve Center; realizará una comprobación rápida y te pedirá que actualices tu software desde la Tienda de Microsoft.
- Instala el Lenovo Nerve Center desde la Tienda de Microsoft.
- ¡Y listo! Ya tienes nuevamente el Lenovo Nerve Center en tu equipo.
Espero que este truco te haya servido; para mí, en el día a día, esta herramienta me es fundamental en mis tareas de trabajo de edición de gráficos y video. Es ruidoso el ventilador, lo sé, pero funciona.
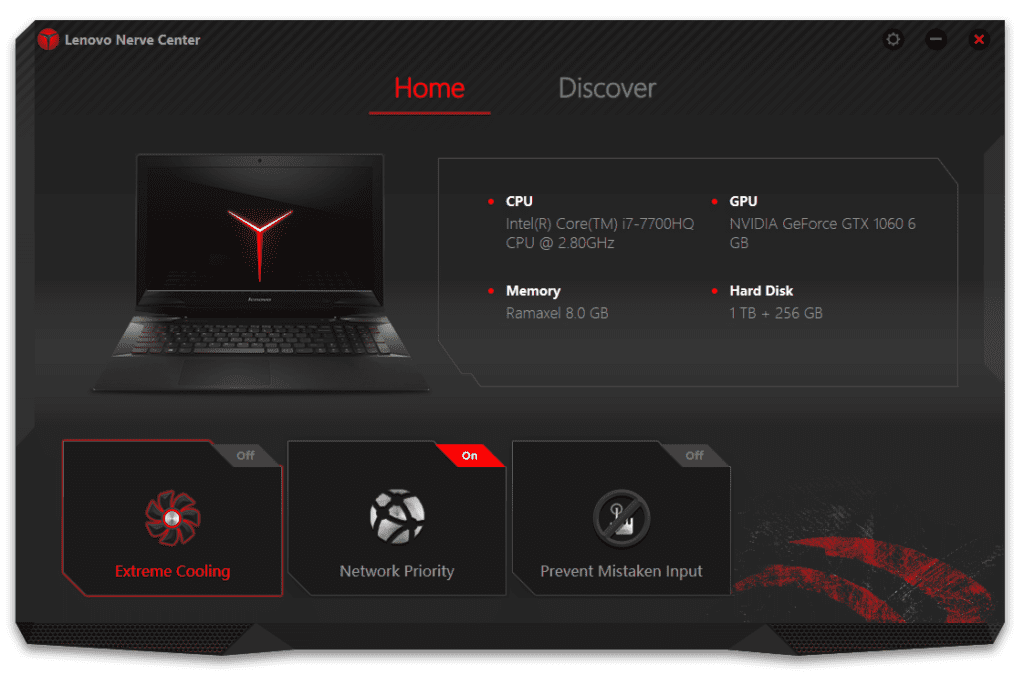
Tip adicional sobre este tema
Sin el software Lenovo Nerve Center, un par de botones del teclado más, quedarían inutilizados:
- El botón de grabación / captura de video de la pantalla de tu computadora (muy útil para aquellos Gamers a quienes les gusta grabar sus partidas de videojuegos).
- La función de la tecla de inicio del software Lenovo Nerve Center.
Algo pasó por ahí; desconozco las razones por las cuales Lenovo decidió descartar esta herramienta, pero aquí la tienes de nuevo. En verdad, espero que te sirva.
Configurar un servidor de archivos Samba en Ubuntu

En casi cualquier institución educativa, organización, empresa, negocio u hogar, es muy común que tengamos alguna computadora o equipo que ya no utilicemos, se encuentre un poco obsoleto, o simplemente esté en desuso. Por ello, te voy a enseñar a configurar un servidor de archivos Samba en Ubuntu con el propósito de que puedas recuperar y darle nueva vida a ese dispositivo.
Veamos: en el ámbito de las redes de área local en donde conviven computadoras con Windows instalado, siempre ha resultado de gran utilidad la posibilidad que crear carpetas compartidas mediante las cuales, podamos transferir fácilmente documentos, guardar música, crear respaldos de información, etc.
En este sentido, si bien es cierto que tanto Mac como Windows disponen esta función de manera nativa o bien, existen alternativas en la nube como NextCloud (un día de estos haremos un tutorial sobre ello), también es cierto que puedes configurar un servidor de archivos Samba independiente asociado a cuentas de usuario para agregar una capa de seguridad independiente a la de tu sistema operativo, accesible desde Internet, y que cumple estándares para “crear” unidades compartidas de red.
Instalación de Samba
Para lograr lo anterior, y partiendo del punto de que dispones de una instalación de GNU/Linux Debian, Ubuntu, LinuxMint o derivadas, lo primero que tienes que hacer es realizar la instalación de los paquetes de Samba. Para ello tecleamos:
sudo apt install samba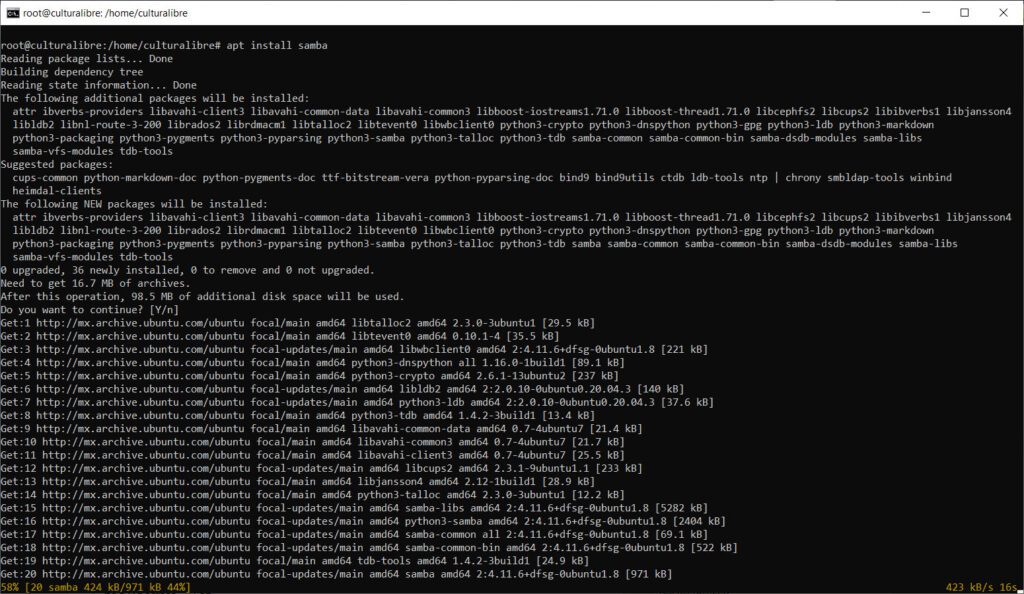
Configuración de Samba
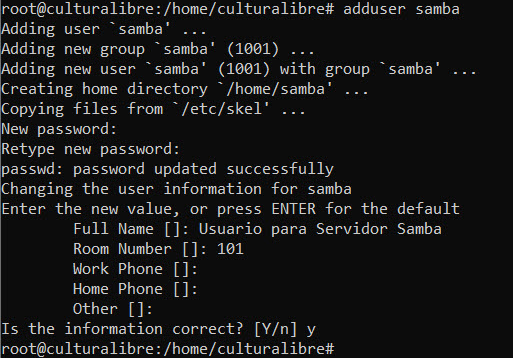
Ahora, crearemos una cuenta de usuario en nuestro sistema operativo (para nuestro caso, crearé el usuario “samba”) mediante el siguiente comando:
sudo adduser sambaSolo deberás asignarle una contraseña y completar algunos datos (si así lo deseas) para identificar y completar información de tu usuario:
Tip: si en algún momento en el futuro deseas cambiar la contraseña a tu usuario, solo deberás teclear algo como esto:
sudo passwd sambaAhora, si todo ha salido bien, es momento de modificar el archivo de configuración de Samba que se ubica en /etc/samba/smb.conf; para ello, utilizaremos el editor de texto nano, con lo cual es pertinente teclear:
sudo nano /etc/samba/smb.confA continuación, verás una pantalla como esta:
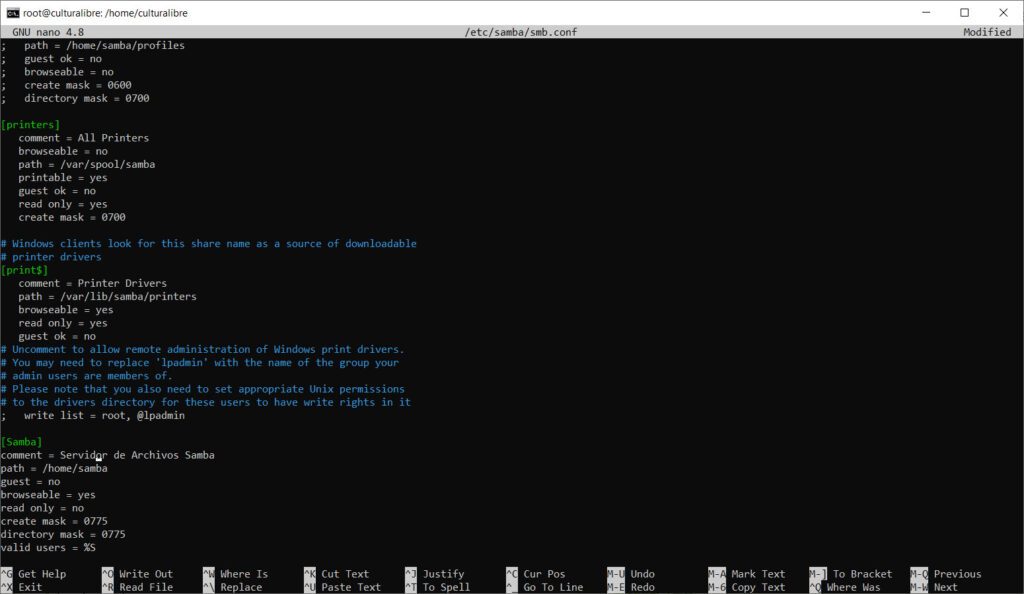
Solo debes ir al final del archivo y añadir la siguiente configuración:
[Samba]
comment = Servidor de Archivos Samba
path = /home/samba
guest = no
browseable = yes
read only = no
create mask = 0775
directory mask = 0775
valid users = %SGuarda los cambios en nano (presionando CTRL + O y Y) y regresemos a la consola (presionar letra Q). Con ello, deberemos ahora agregar el usuario Samba al servidor de archivos Samba (valga la redundancia) mediante el siguiente comando:
smbpasswd -a sambaAl hacer lo anterior, te pedirá que ingreses una clave de usuario de Samba; asimismo, puedes ver en todo momento el estado del servicio Samba en tu computadora tecleando el comando:
sudo service smbd status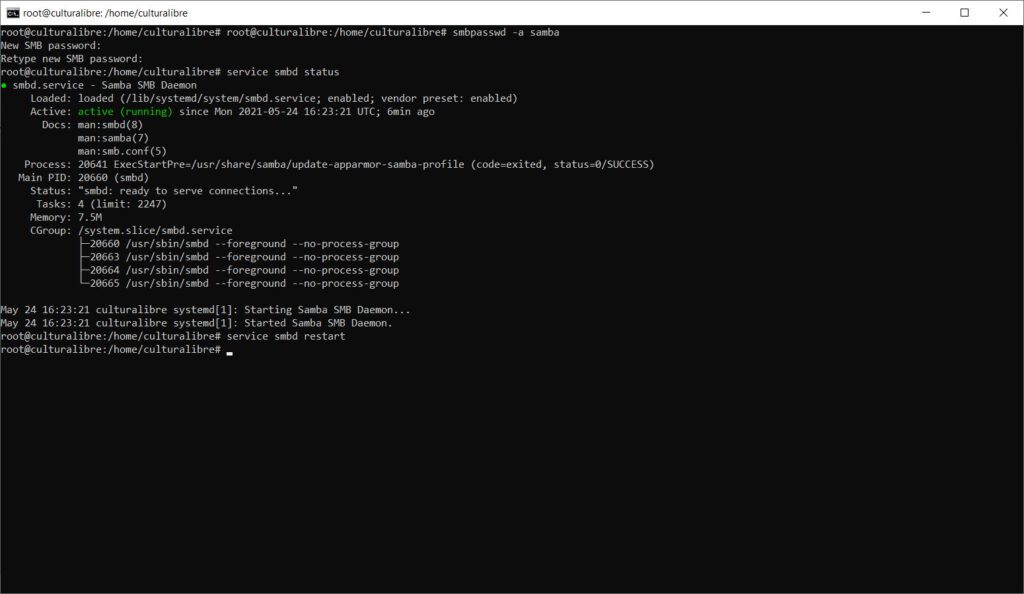
…o bien, puedes reiniciar el servicio ejecutando el siguiente comando también:
sudo service smbd restart¿Cómo conectarte a tu servidor de archivos Samba desde Windows?
Si has seguido los pasos anteriores, tu servidor Samba está listo para funcionar; para acceder al mismo desde Windows, lo primero que tienes que saber es la IP que tiene asignada dentro de tu red de área local. Para ello, ejecuta el comando IP en Linux:
ip a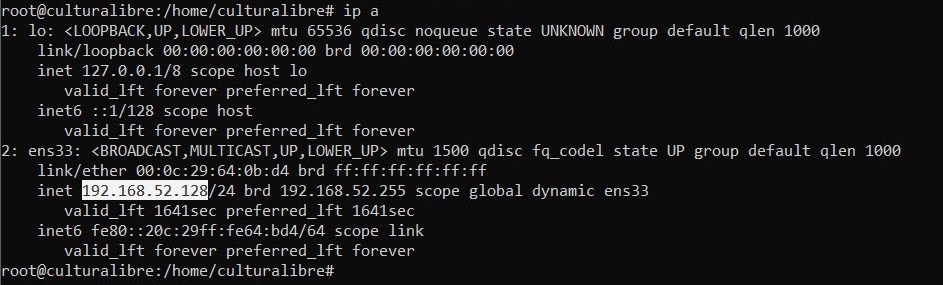
En el caso del presente ejemplo, la IP que tiene mi computadora con Samba es la 192.168.52.128; así, solo tienes que abrir una ventana del Explorador de Windows y teclear algo como sigue y presionar Enter:
\\192.168.52.128\samba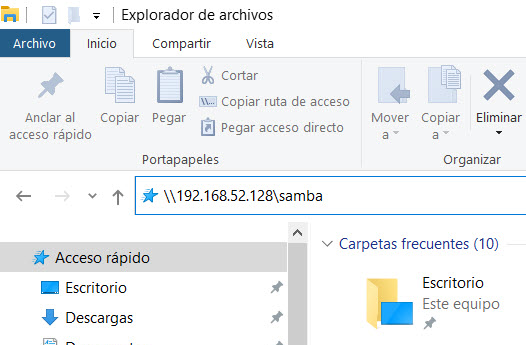
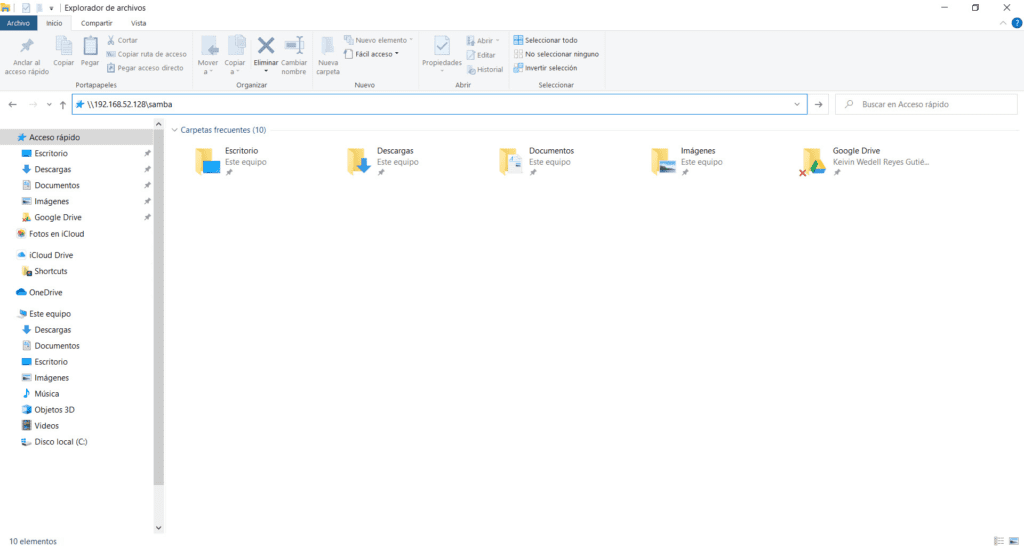
Es muy importante que utilices la diagonal invertida; en tu teclado, la puedes obtener presionando la tecla ALT DERECHA + la tecla ? (la que está justo a la derecha del cero). Si todo ha resultado correcto, inmediatamente se te desplegará un cuadro de información como el que sigue:
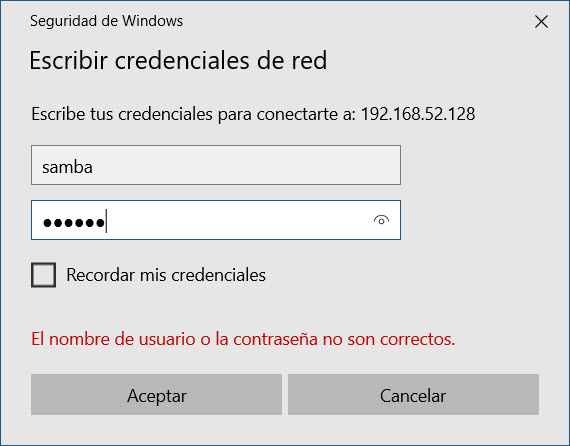
Aquí, solo resta ingresar el nombre de usuario y contraseña que configuraste al inicio, y activar la opción “recordar credenciales”, si así lo deseas, para evitar tener que teclearla en cada ocasión que desees acceder. Con esto, ¡ya tienes listo tu servidor Samba para almacenar archivos!
Añadir tu servidor Samba como una unidad de disco de red
Hasta el paso anterior, tenemos un servidor Samba funcional. No obstante, resulta ser muy cool el poder añadir mi servidor de archivos como “una unidad de red” en mi explorador en Windows.
Para hacer esto, es muy fácil: con una ventana del explorador de archivos abierta, haz clic con el botón derecho del mouse sobre el icono “Red” y selecciona la opción “Conectar a una unidad de red”.
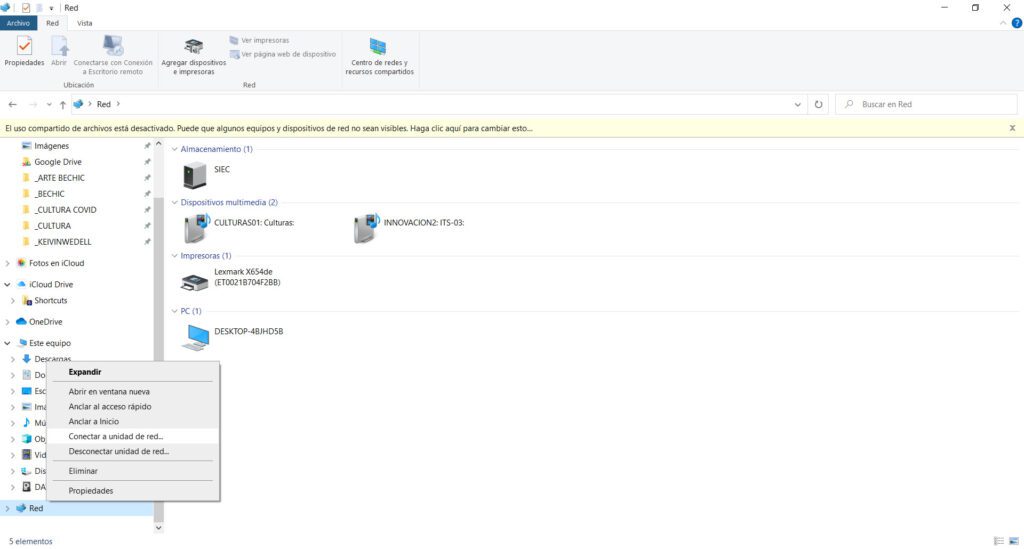
Acto seguido, Windows te solicitará que asignes una letra a tu “nueva” unidad de disco, así como la ruta de acceso al “recurso compartido”. Para ello, deberás ingresar la IP y nombre de usuario de tu servidor Samba; en mi caso:
Unidad: Z:
Carpeta: \\192.168.52.128\samba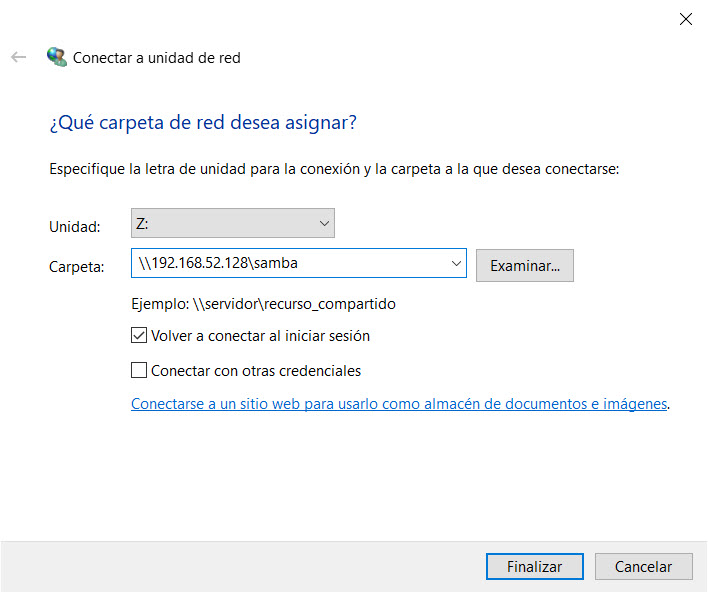

¡Y listo! Sólo deberás teclear nuevamente tu nombre de usuario
y contraseña creados en cada ocasión que desees acceder si es que no activaste la opción “Recordar credenciales”.
Si en algún momento deseas desconectar tu red, solo presiona botón derecho sobre una unidad de red existente, y selecciona la opción “Desconectar”.
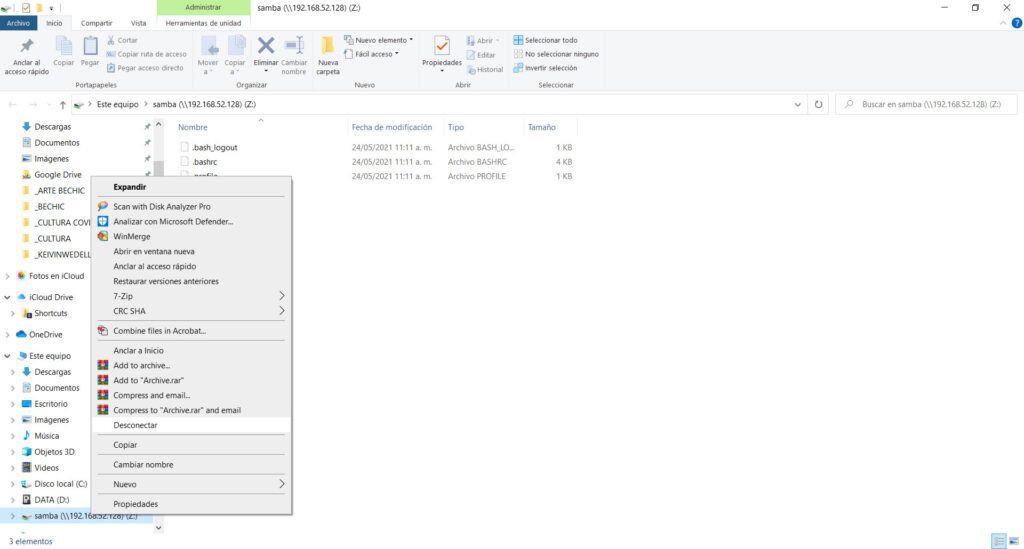
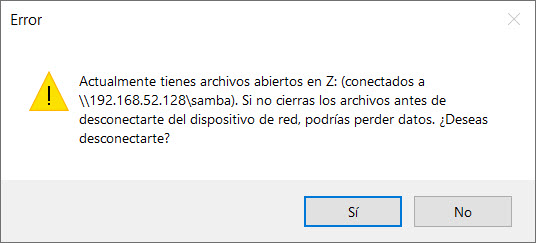
¡Espero que te sirva!
Configurar una tarjeta de red con WPA desde la línea de comandos en Ubuntu

En mi oficina, tengo una vieja laptop a la cual, el monitor de cuando en cuando deja de funcionar sin forma de volver a encenderlo nuevamente. Con ello en consideración, decidí tomar esta laptop para configurarme un modesto servidor conUbuntu Server 14.04 LTS en el cual tengo habilitado Apache, PHP y MySQL principalmente con la cual te mostraré cómo conigurar una tarjeta de red con WPA desde la línea de comandos en Ubuntu.
Es pertinente comentar en este que punto que para el presente tutorial, procedí a realizar una instalación limpia de Ubuntu Server 14.04, configuré mi tarjeta de red, particiones y demás, pero al concluir el proceso de reinicio posterior a la instalación.
Así, para lograr que Ubuntu “inicie” y se “conecte” automáticamente a una red WPA, tenemos que seguir los siguientes pasos desde la consola o línea de comandos:
1.- Averiguamos en primer lugar el nombre de nuestra interface de red inalámbrica (generalmente es wlan0):
iwconfig2.- Creamos el archivo de configuración del demonio de administración de redes wpa_supplicant…
sudo nano /etc/wpa_supplicant/wpa_supplicant.conf…y guardamos dentro del mismo los siguientes valores:
ctrl_interface=/var/run/wpa_supplicant
network={
ssid="NOMBRE-DE-RED-WIFI"
key_mgmt=WPA-PSK
psk="CONTRASEÑA-WIFI"
}3.- Ahora, iniciamos el demonio wpa_supplicant mediante el siguiente comando:
sudo wpa_supplicant -c/etc/wpa_supplicant/wpa_supplicant.conf -iwlan0 -B4.- “Levantamos” nuestra tarjeta de red…
sudo ifconfig wlan0 up5.- Pedimos ahora una dirección IP al servidor DHCP activo:
sudo dhclient wlan06.- Con ello, si hacemos un ping a google.com, deberías de obtener ya una respuesta. Pero bien, para que nuestra configuración se cargue en cada reinicio, abrimos el archivo /etc/network/interfaces…
sudo nano /etc/network/interfaces…y nos aseguramos de añadir lo siguiente:
auto wlan0
iface wlan0 inet dhcp
wpa-ssid NOMBRE-DE-RED-WIFI
wpa-psk CONTRASEÑA-WIFI7.- Para comprobar que el demonio wpa_supplicant se iniciará automáticamente en cada inicio del sistema, ejecutamos los siguientes comandos:
sudo /etc/init.d/networking stop
sudo /etc/init.d/networking start¡Y es todo!
Si deseas profundizar mucho más en el tema u obtener información para realizar un proceso similar para redes WEP, te recomiendo hacer clic en este enlace, el cual te llevará a un excelentísimo artículo que habla con gran detalle sobre este proceso.
Sponsors of Tomorrow

Este año, Intel ha tenido la fantástica idea de lanzar un campaña publicitaria llamada “Sponsors of Tomorrow” que, para los que nos encontramos involucrados en la cultura hacker, explorando horizontes y buscando de soluciones tecnológicas simples para la vida cotidiana de las personas, nos permite dibujarnos una gran sonrisa, recordar quiénes somos e inspirarnos para ser mejores cada día. En el primer spot, con mucho humor Intel nos presenta a Ajay Bhatt, co-inventor del puerto USB (el estándar) como un rockstar de la ingeniería. Disfruta la lista completa de videos de la serie de Intel Sponsors of Tomorrow, ¡que la disfrutes!
El primer servidor web de la historia

En 1989, Tim Berners-Lee le presentaba a su jefe en el CERN, Mike Sendall, una propuesta “vaga, pero interesante” para el desarrollo de un sistema de comunicación basado en hipertextos (HTML) y comunicación entre redes de computadoras a través de un protocolo de Internet (HTTP) con el fin de permitir a la comunidad científica del mundo, poder trabajar de manera colaborativa, compartir e intercambiar información en sus actividades de investigación, por lo que el 6 de agosto de 1991, fue puesto en funcionamiento el primer Servidor Web de la historia en el CERN, el cual fue instalado en una computadora NeXT Cube de la emprese de Steve Jobs (el fundador de Apple, quien después de su despido, se había aventurado a fundar otra compañía llamada NeXT Computer Inc.)
Este servidor Web recibió el nombre de httpd, que corresponde a las siglas de “hypertext protocol daemon”, un nombre que hoy se sigue usando en algunas distribuciones linux para lanzar el servidor web Apache como Fedora o CentOS. Como dato curioso, se puede leer aún en una pegatina sobre la carcasa que dice “THIS MACHINE IS A SERVER. DO NOT POWER IT DOWN!!”

También, este año, Tim Berners-Lee publicó las especificaciones finales para la construcción de documentos HTML (HyperText Markup Language) mediante 22 elementos (en la versión 1.0), de los cuales hoy en día (en la versión 4.x), todavía son usados trece.
El primer servidor de Google

Hace algunos meses, casualmente encontré una foto de lo que fue el servidor Web de Google que Larry Page y Sergey Brin (co-fundadores y propietarios de la empresa establecida en Mountain View), mismo en el cual montaron su famoso buscador y, con ello, la tecnología PageRank: un sistema que lo que hace es buscar en los “backlinks” para encontrar e indexar información.

Llamado originalmente Backrub, al buscador le es asignado el nombre de Google (un juego de palabras que viene del número gúgol [googol] – término improvisado por el sobrino de nueve años de Edward Krasner, Milton Sirotta, en 1938, que representa el 10 elevado a la 100 – y las gafas conocidas como goggles) y comienza a funcionar en google.stanford.edu, un sitio en donde dan las primeras imágenes de los servidores austeros desde los cuales operan. Según la Wikipedia, comienzan a arreglárselas haciendo diseños similares a los de Lego.
Es impresionante lo que una buena idea puede desencadenar.
Les recomiendo la historia de Google aquí: http://es.wikipedia.org/wiki/Google#Historia_de_Google
Así como también, algunas fotos tomadas en el Computer History Museum desde aquí: http://www.flickr.com/photos/jurvetson/sets/257763
Debe estar conectado para enviar un comentario.