Categoría: GNU/Linux
-

DNS dinámico con Dynu
Si eres un entusiasta del software libre, te enseñaré a configurar un DNS dinámico con Dynu, un estupendo servicio que no tiene nada qué pedirle a viejos conocidos como no-ip.com o dyndns, por ejemplo ya que seguramente has tenido en algún momento la necesidad de montarte tu propio servidor web utilizando el servicio de Internet…
-
¿Cuántos usuarios soporta Moodle?
Si eres administrador de plataformas de e-learning, director de una escuela, administrador de sistemas o profesor, seguramente te habrás preguntado en alguna ocasión cuántos usuarios soporta Moodle. No hay una respuesta simple o sencilla para ello ya que depende de varios factores por lo que en este artículo, te ayudaré a tener una mayor comprensión…
-
Activar permisos de escritura a particiones Windows desde Linux
Si eres usuario de una computadora con dual boot instalado para trabajar con Windows y Linux, es muy probable que hayas tenido el problema de no poder “escribir”, crear directorios, copiar, pegar o mover archivos en la propia partición donde está instalado Windows por lo que en esta ocasión, te mostraré cómo configurar tu equipo…
-
Encender el ventilador de una laptop Acer Predator Helios 300 PH315-51 en Linux
La línea Predator de computadoras tipo laptop de Acer, incorporan un software llamado PredatorSense a través del cual, como usuarios, podemos controlar el encendido o apagado (manual o automático) de nuestra computadora. Desafortunadamente, PredatorSense solo funciona en Windows por lo que, aquellos usuarios que utilizamos sistemas operativos alternativos basados en GNU/Linux, no podemos disponer de…
-
Sincronizar la hora entre Windows y Linux
Si tienes instalada alguna distribución GNU/Linux conviviendo con Windows, es muy probable que te resulte molesto (y necesario) sincronizar la hora entre Windows y Linux. Este “detalle” (porque no es un problema realmente), se debe a que estos ambos sistemas operativos, gestionan de manera distinta el tiempo: en el caso de una gran mayoría de…
-
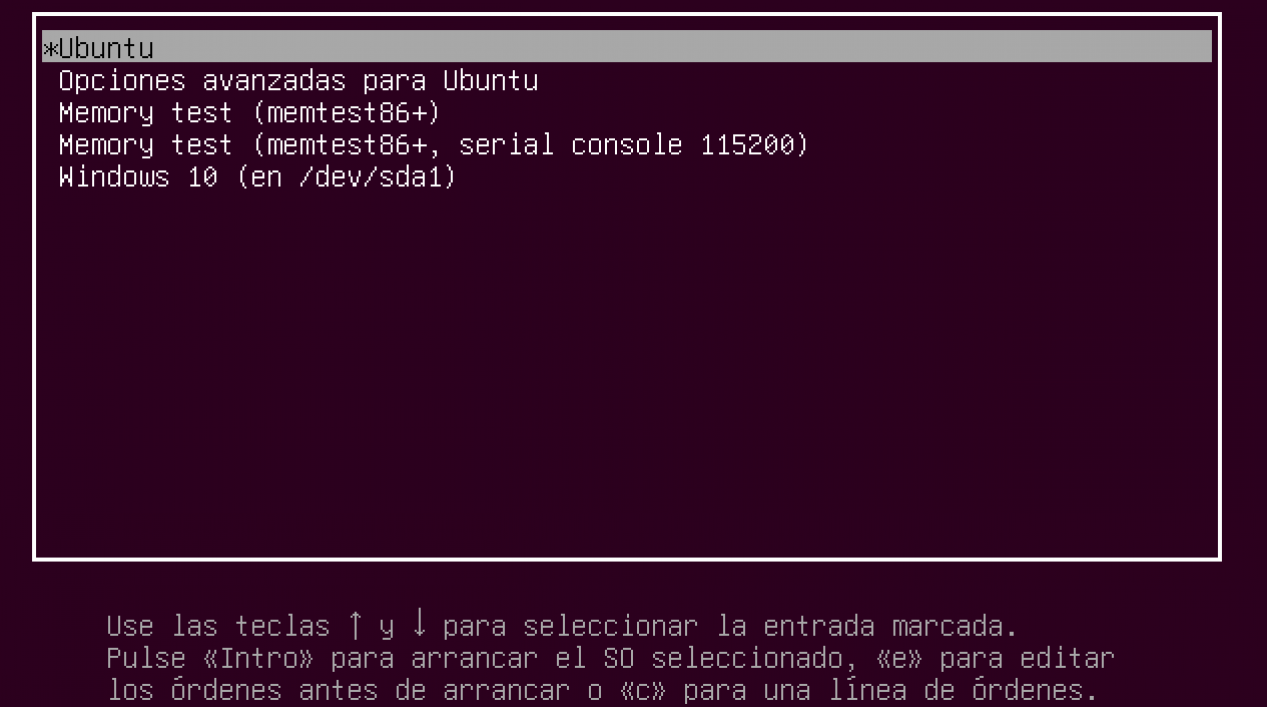
Recordar el último sistema operativo en Linux
Si eres instalaste alguna distribución de GNU/Linux en tu computadora y la configuraste para convivir junto con Windows, seguramente te podrá resultar “molesto” que tu distribución sea la primera en iniciar cada que enciendes tu computadora; por ello, para que tu computadora pueda recordar el último sistema operativo en Linux, solo debes seguir los siguientes…
-
Configurar un servidor de archivos Samba en Ubuntu
En casi cualquier institución educativa, organización, empresa, negocio u hogar, es muy común que tengamos alguna computadora o equipo que ya no utilicemos, se encuentre un poco obsoleto, o simplemente esté en desuso. Por ello, te voy a enseñar a configurar un servidor de archivos Samba en Ubuntu con el propósito de que puedas recuperar…
-
Configurar una tarjeta de red con WPA desde la línea de comandos en Ubuntu
En mi oficina, tengo una vieja laptop a la cual, el monitor de cuando en cuando deja de funcionar sin forma de volver a encenderlo nuevamente. Con ello en consideración, decidí tomar esta laptop para configurarme un modesto servidor conUbuntu Server 14.04 LTS en el cual tengo habilitado Apache, PHP y MySQL principalmente con la cual te…
-
Bloquear accesos por país con Firewall CSF
Para todos aquellos que en algún momento tengan la necesidad de desarrollar actividades de administración de un servidor Web bajo GNU/Linux, descubrirán que Internet es un entorno más que propicio tanto para la colaboración o distribución de contenidos, como también, para prácticas maliciosas o ataques informáticos por lo que seguramente te resultará de gran utilidad…
-
Análisis de logs de Apache con Scalp!
En temas de seguridad y protección de servidores, no existe nada mejor que proteger los mismos con aplicaciones de detección de intrusiones como Snort (https://www.snort.org/) o Suricata (http://suricata-ids.org/) u otras ofertas comerciales basadas tanto en hardware (firewalls) como Software (http://www.acunetix.com/) o servicios en la nube (https://www.cloudflare.com/) que actualizan con mayor regularidad sus bibliotecas y/o diccionarios…