Tengo una Laptop Lenovo Legion Y720 desde la cual realizo tareas de diseño, edición de video y trabajo con la web desde 2 sistemas operativos distintos. En GNU/Linux Ubuntu 20.04 LTS todo funciona bien, pero en Windows 10 no por lo que me di a la tarea de solucionar error en menú contextual mediante una pulsación con dos dedos (tap two fingers) me resulta indispensable en entornos gráficos.
Cuando la compré, noté que la función de mostrar el menú contextual (clic con el botón derecho del mouse) utilizando un “tap” a dos dedos (tap two finger) no funcionaba en Windows 10 pero en GNU/Linux sí.
Con ello, me dí a la tarea de buscar e instalar drivers originales, asignar valores de fábrica, mover configuraciones en el Panel de Control en Windows en donde, a pesar de que las configuraciones debían de resolver la posibilidad de obtener el menú contextual a 2 dedos, no lo hacían.
Generalmente, uno accede a las propiedades del mouse de la computadora para realizar configuraciones adicionales del dispositivo.
No obstante, al acceder a las configuraciones de Elan, en apartado “Varios dedos”, aún y cuando tengas la configuración del “Clic” a “Dos dedos” activada, el menú contextual no funciona; no importa si lo activas o desactivas múltiples veces: lo único que hace es poner el valor de 7 a Tap_Two_Finger y dejar en blanco otros valores del registro de Windows. Por ello, te ofrezco la solución más abajo.
Solucionar error en menú contextual para activar tap two fingers en una Lenovo Legion Y720
Revisando en un foro y otro, así como experimentando y comparando valores en el Registro de Windows, por fin pude dar con la solución; si tienes una computadora Lenovo Legion Y720 y no puedes obtener el menú contextual con 2 dedos, esto es lo que tienes que hacer:
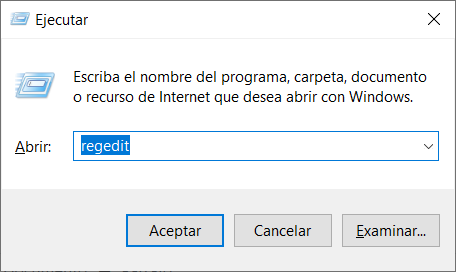
Presiona la combinación de tecla Windows + R
Escribe “regedit” y presiona enter
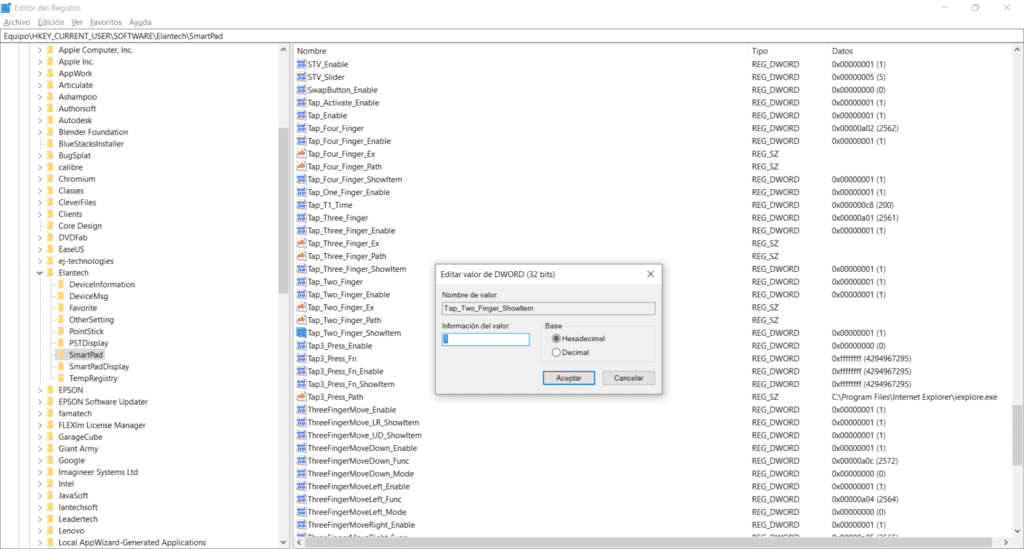
Busca / dirígete a la siguiente clave de registro: HKEY_CURRENT_USER\SOFTWARE\Elantech\SmartPad
Abrimos el editor del registro de Windows
Ahora bien, una vez dentro de la carpeta SmartPad, haz doble clic sobre los siguientes registros y asígnales el valor de 1:
Tap_Two_Finger
Tap_Two_Finger_Enable
Tap_Two_Finger_ShowItem
Aquí podrás encontrar los registros a modificar para corregir el menú contextual en tu laptop Lenovo Legion Y720
Hecho lo anterior, solo tienes que reiniciar tu computadora, y el tap con dos dedos debería ya de funcionar. ¡Espero que te haya servido!
Me he animado a elaborar este reporte de vulnerabilidad en router Huawei HG8245H de TotalPlay debido a que en días pasados, unos amigos resultaron víctimas de un fraude bancario por Internet debido a esta “falla” en el servicio que te voy a documentar. Pero primero, veamos algunos conceptos:
¿Qué es el Phishing?
El Phishing, es el conjunto de “técnicas” o “prácticas” basadas en el engaño a una víctima ganándose su confianza, haciéndose pasar por una persona, empresa o servicio de confianza (suplantación de identidad de tercero de confianza), para manipularla y hacer que realice acciones que no debería realizar (por ejemplo revelar información confidencial o hacer click en un enlace).
Para realizar el engaño, habitualmente hace uso de la “ingeniería social” explotando los “instintos sociales” de la gente y su “familiaridad” con actividades rutinarias que realiza por costumbre, como puede ser el ayudar o tratar de ser eficiente.
No obstante lo anterior, a veces también hace uso de procedimientos informáticos que aprovechan vulnerabilidades de software o hardware, lo cual implica conocimientos técnicos más complejos.
En casi todos los casos, el objetivo del Phishing es robar información pero, en otros, el propósito es instalar malware, sabotear sistemas o robar dinero a través de fraudes más organizados.
¿Cuál es el problema con el router Huawei HG8245H de TotalPlay?
Básicamente, te he de contar que, la “Empresa “, contrató un servicio de Internet Empresarial de TotalPlay 200, para lo cual les fue proporcionado un router Huawei HG8245H.
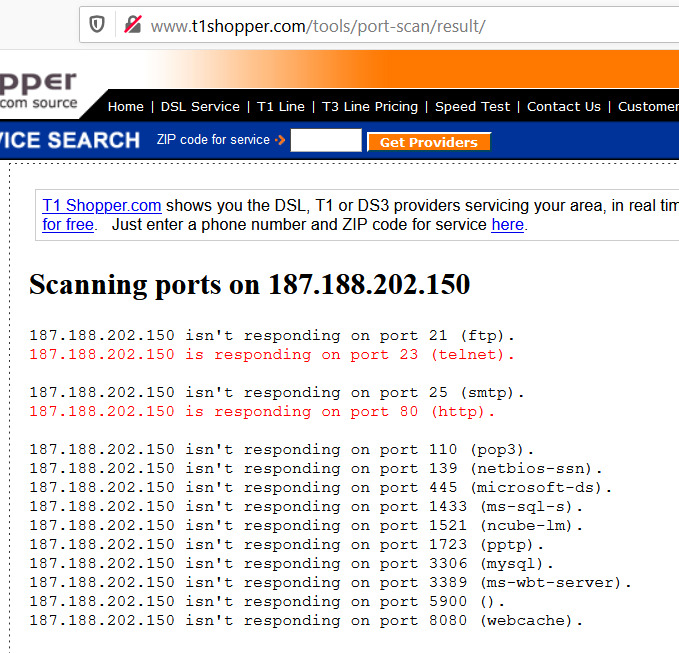
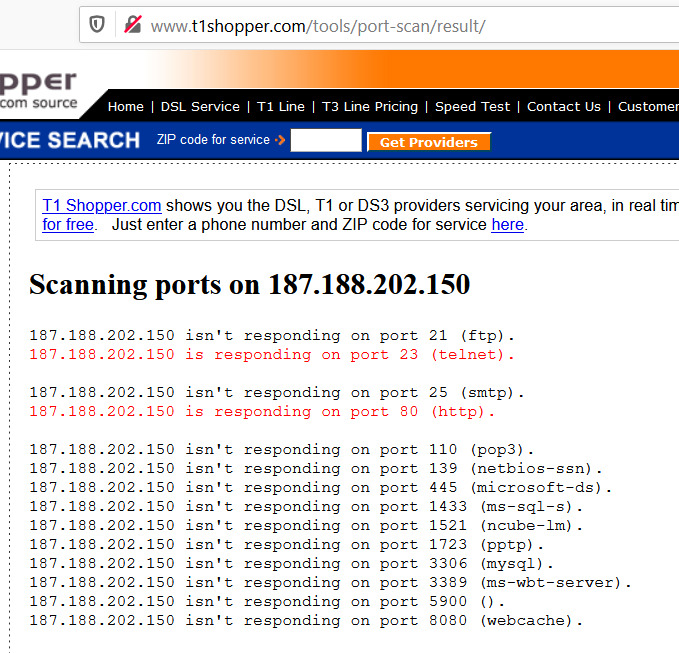
Este dispositivo, por defecto, venía con el puerto 23 habilitado (lo descubrimos después); en este contexto, una necesidad de la organización es la de permitir conexiones en el puerto 80 para dar “salida” a un servidor Web. Así, tanto el puerto 23 como el 80 están “abiertos”.
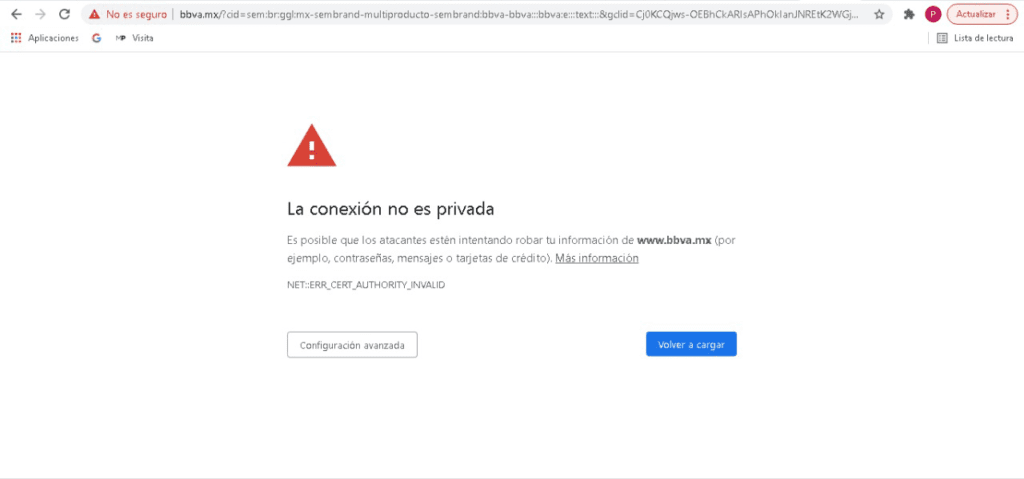
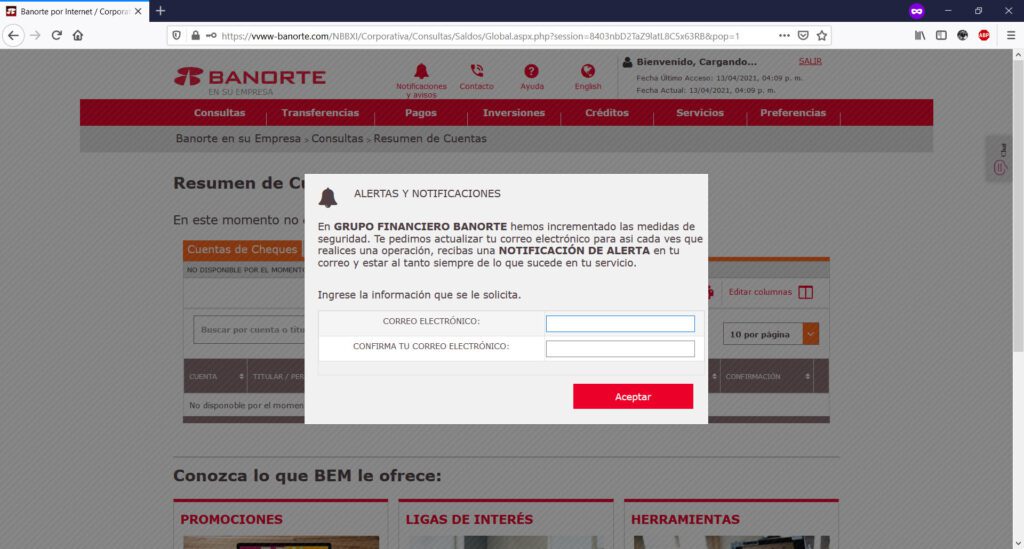
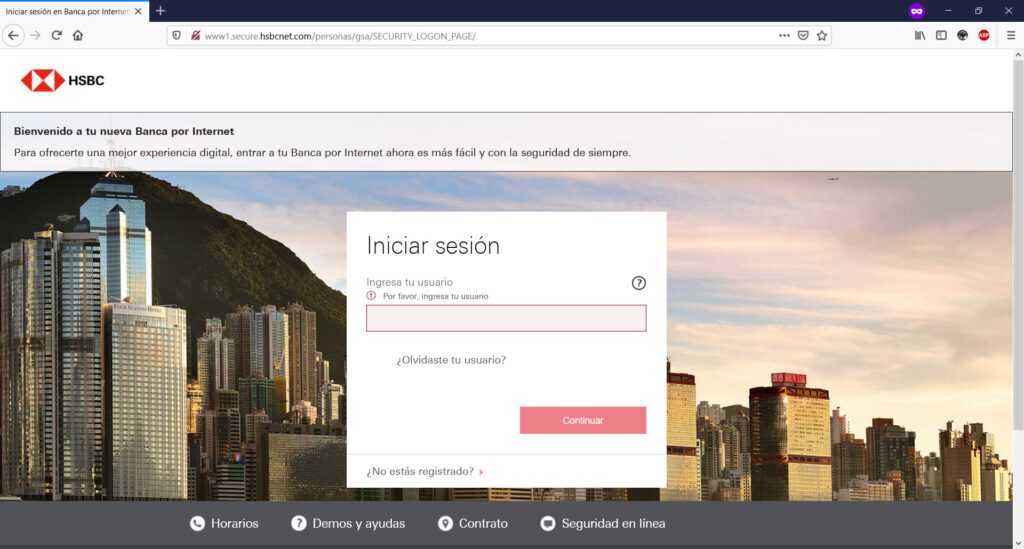
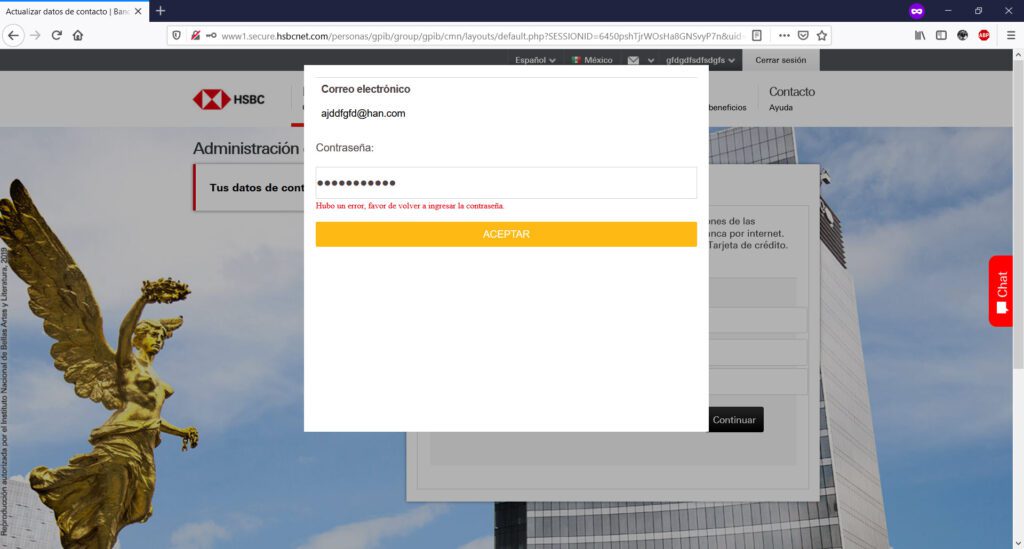
Ahora bien, en esta organización, se comenzaron a presentar redireccionamientos extraños de nombres de dominio de instituciones bancarias, mostrando de manera inicial un mensaje de error, certificados SSL inválidos, y necesidad de “realizar acciones adicionales” y permisos en el navegador para poder “visitar” el sitio web deseado, como por ejemplo, “aceptar” ir a la “Configuración avanzada” y “permitir” alguna excepción o riesgo de uso del certificado SSL para “conectar” con la institución bancaria.
En este sentido, si “aceptamos” continuar bajo nuestro propio riesgo, habremos abierto la posibilidad de que el sitio original de nuestra institución bancaria, sea “resuelta” en un servidor apócrifo que contiene una página clonada de mi banco, cuyo principal objetivo será el obtener claves, números de tarjeta, tokens, información personal, etc.
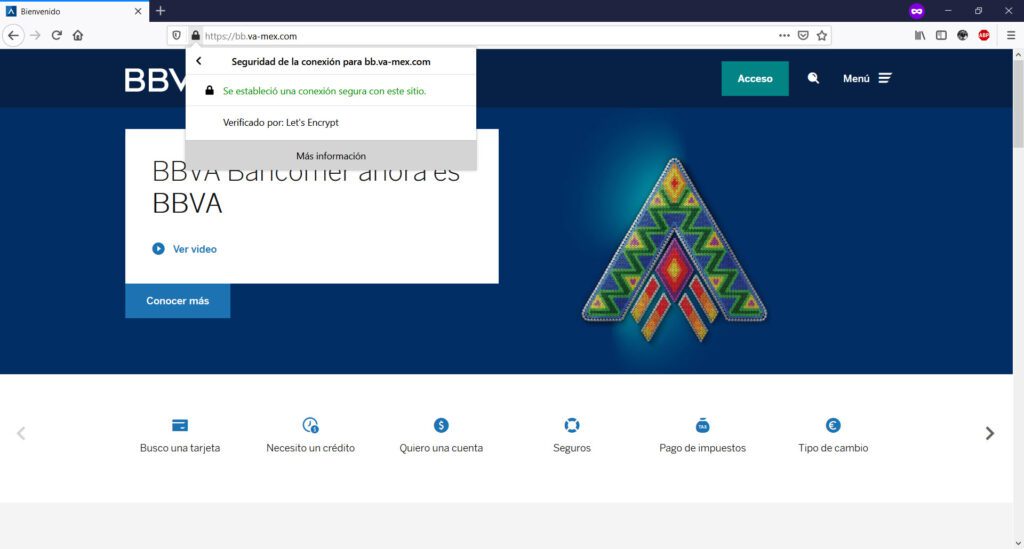
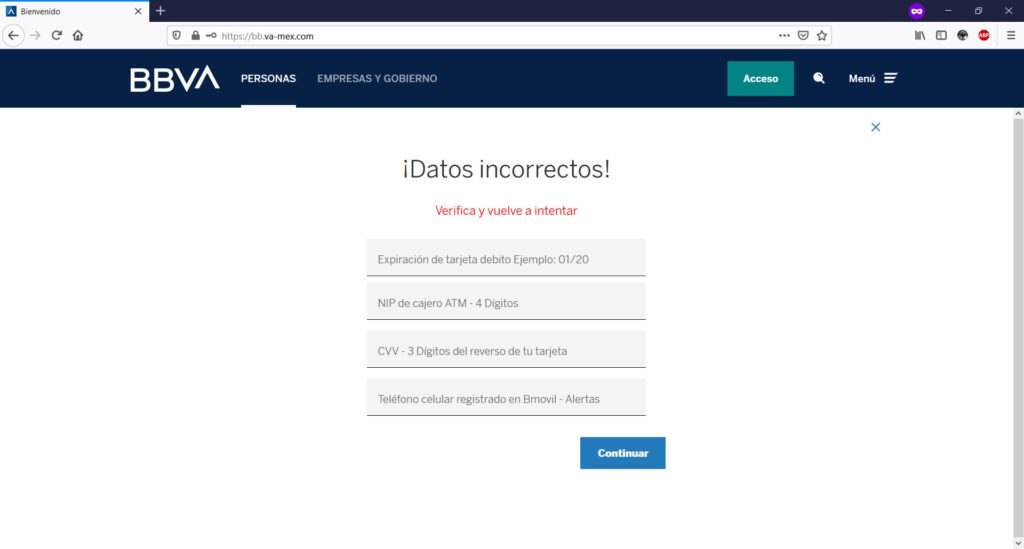
Si observas detenidamente la URL de mi captura de pantalla, podrás observar que la URL de la institución bancaria BBVA.MX ha sido “redireccionada” indebidamente a otro nombre de dominio: el sitio fraudulento, Phishing a la vista.
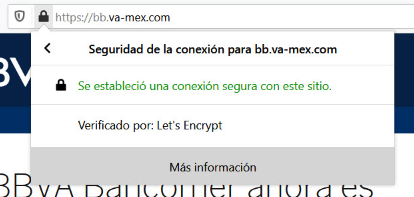
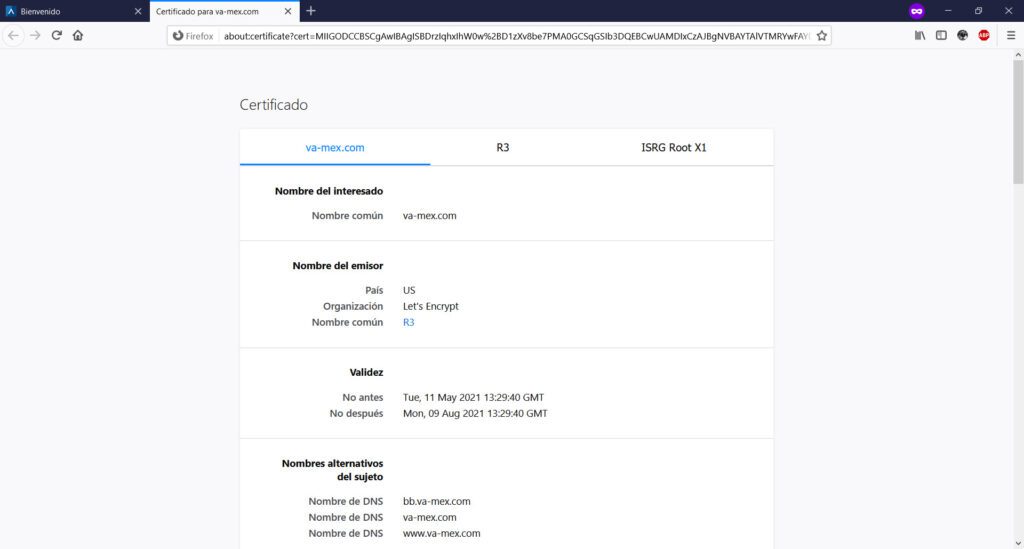
Inclusive, te “presenta” un certificado de seguridad SSL para darte la confianza de que estás navegando en un entorno “segura” aprovechando las firmas de Let´s Encrypt, un estupendo servicio gratuito que ayuda a los desarrolladores o administradores de sistemas a fortalecer la entrega de servicios web cifrados para proveer a nuestros usuarios de un cierto nivel de protección en la red; pero que en este caso, es utilizado maliciosamente para “dar la impresión” de que estamos en un sitio seguro. En sentido estricto, la conexión estará cifrada pero, el sitio web en cuestión tiene una motivación: robarte tus datos. Aquí puedes ver un certificado SSL de una URL fraudulenta o de Phishing…
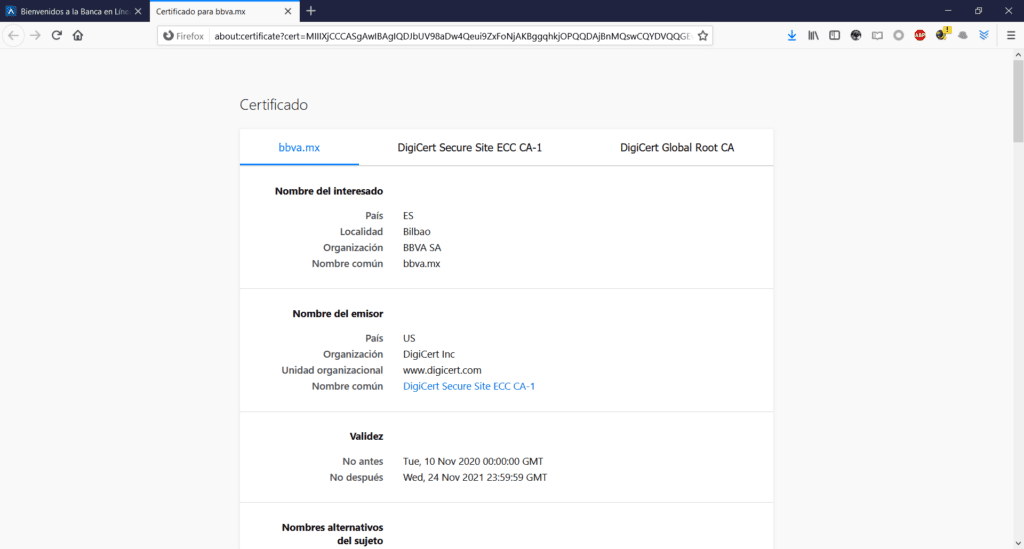
…y aquí puede ver un certificado correctamente autenticado por una autoridad certificadora de una institución bancaria acreditada.
¿Por qué tiene este redireccionamiento mi router Huawei HG8245H de TotalPlay?
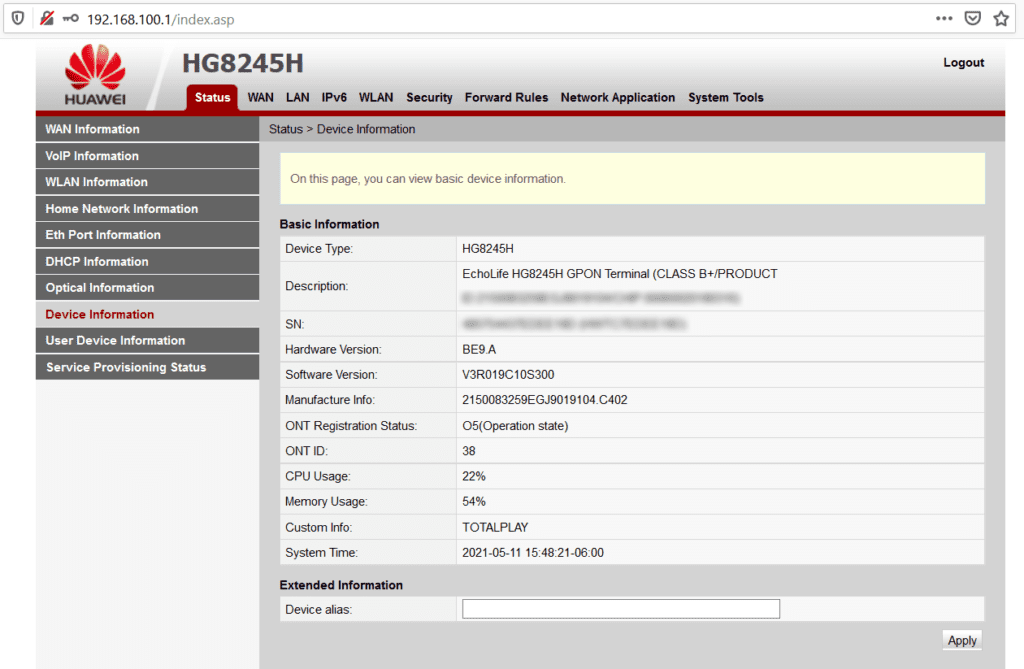
Si eres un usuario no técnico, debes saber que cualquier dispositivo que sirva para “proveerte” de Internet en tu oficina o domicilio, cuenta con un panel de administración para realizar configuraciones adicionales.
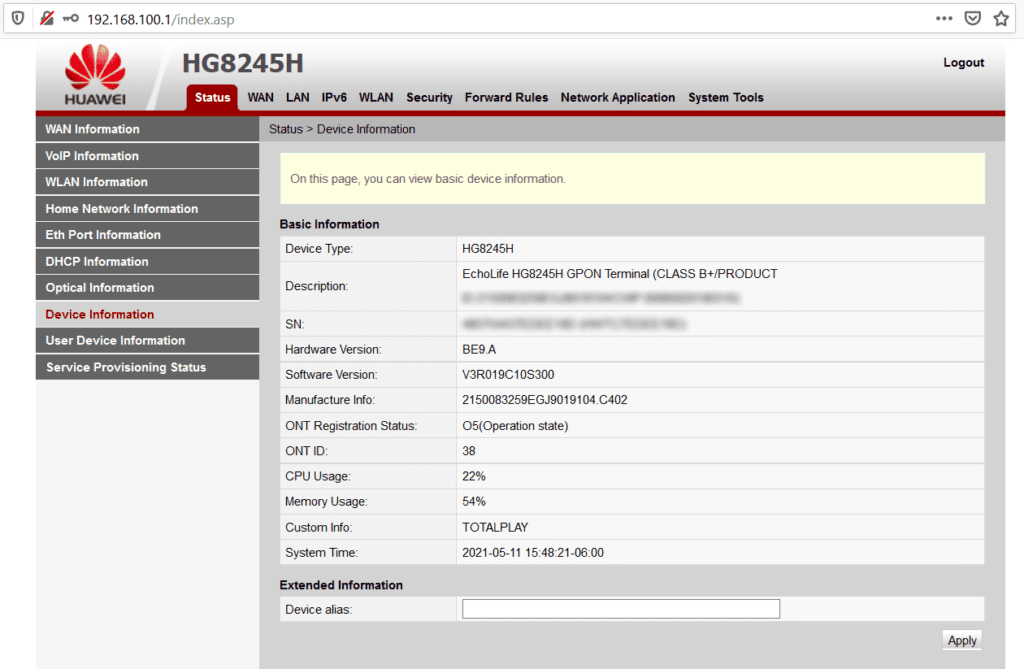
En este sentido, el router Huawei HG8245H de TotalPlay, una vez que te hayas conectado de manera alámbrica o inalámbrica al mismo, puede administrarse accediendo a la IP 192.168.100.1 desde tu navegador.
Un primer problema es que, de fábrica, viene configurado para su acceso con los siguientes datos:
Usuario: root
Password: admin
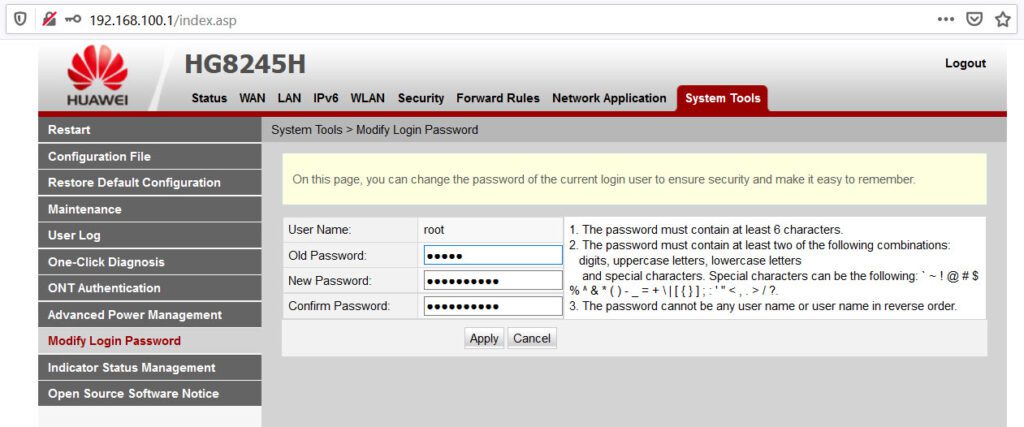
Así, empleando estos datos, alguien dentro de tu red podría “aprovecharse” del dispositivo y realizar configuraciones indebidas. Aquí, puedes ver una captura de pantalla del panel de administración del router.
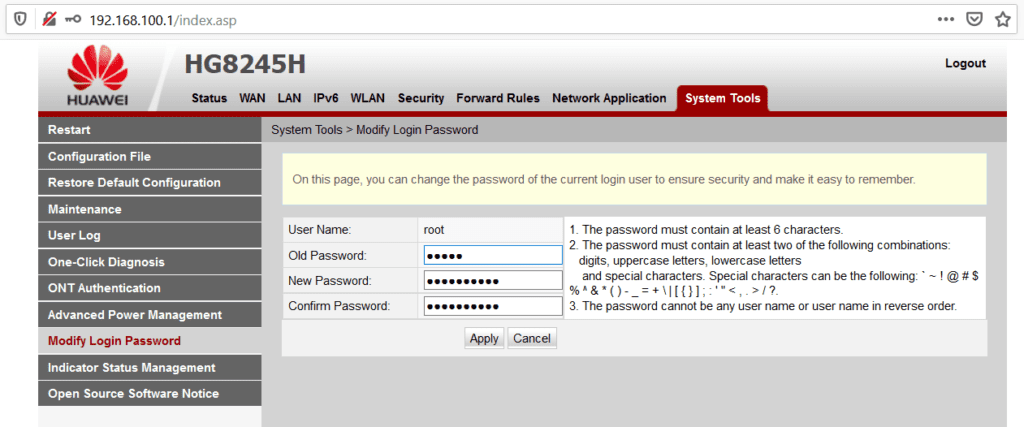
Una buena práctica para “dificultar” el acceso no autorizado al dispositivo es cambiar la contraseña de administración. Esto puede hacerse fácilmente accediendo a la pestaña “System Tools” y opción “Modify Login Password” para cambiar la contraseña.
En sentido estricto, si no cambias la contraseña de administración con la cual viene el router de fábrica, tienes una grave vulnerabilidad ahí que puede explotar, teóricamente, un usuario mal intencionado que esté conectado a tu red interna.
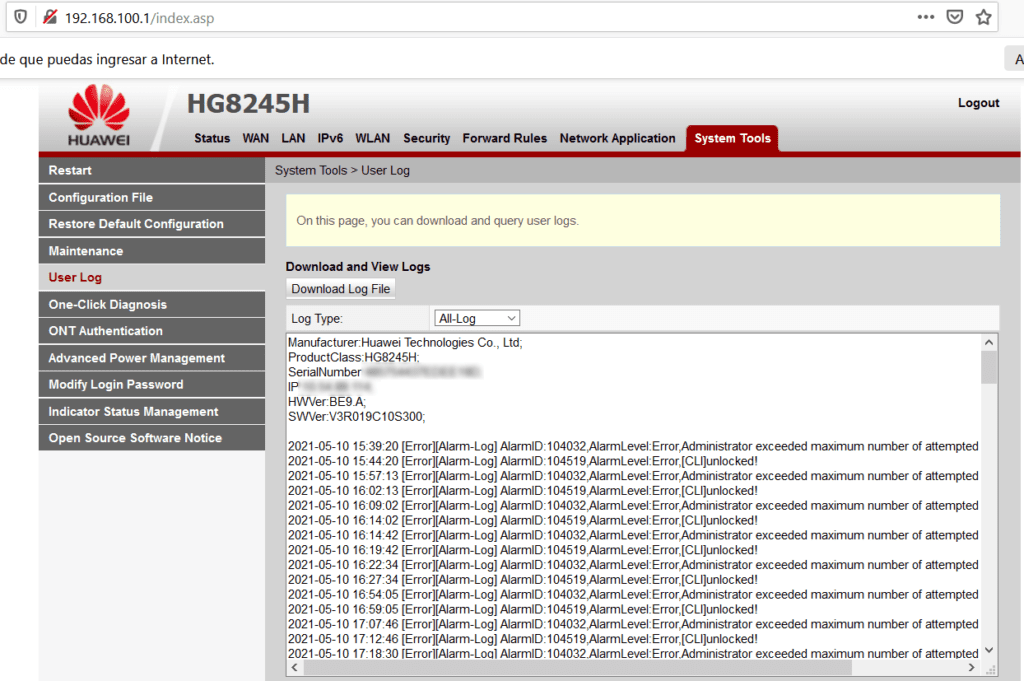
No obstante lo anterior, me ha pasado que, a pesar de que cambie la contraseña de acceso al dispositivo, inexplicablemente es vulnerado en sus configuraciones. Aquí, tengo mis sospechas sobre el puerto 23 que permite conexiones mediante Telnet que me ha dejado abierto TotalPlay por razones que desconozco.
Además, estas sospechas sobre el puerto 23 se incrementan en el sentido de que, revisando registros de acceso al panel de administración mediante su portal Web, no muestra ninguna evidencia de acceso no autorizado a través del mismo, pero sí intentos recurrentes de acceso al dispositivo.
La manipulación de nombres de dominio mediante configuración DNS en router Huawei HG8245H de TotalPlay
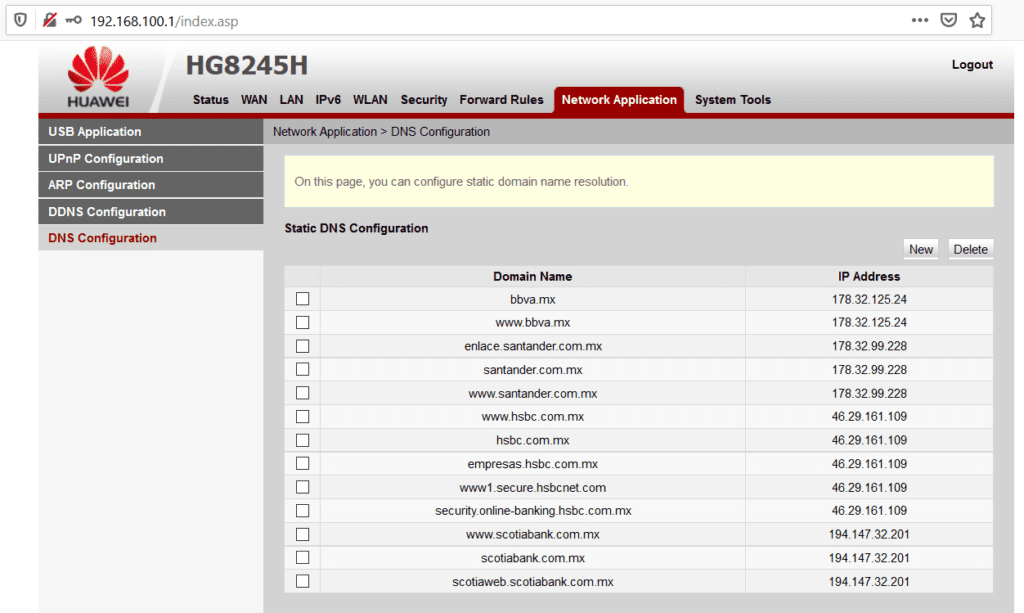
Y aquí llegamos al punto: el atacante malicioso (que me da la impresión, puede acceder desde la red interna de TotalPlay o bien, de mi propia red interna mediante algún equipo infectado con malware), “modifica” y “redirecciona” los destinos de “resolución” de un nombre de dominio, suplantando los registros DNS originales por otros que sin ningún inconveniente pueden ser “resueltos” mediante redireccionamiento en un servidor que haya configurado e instalado para tal propósito. Te explico:
https://bbva.mx es el sitio web de un banco español que tiene operaciones en México; haciendo un ping simple desde una red no comprometida, está “apuntado” a la IP 23.3.212.126 para su correcto funcionamiento.
Sin embargo, nuestro atacante malicioso y mal intencionado, implementa configuraciones como estas para “apoderarse” de nuestra conexión y llevarnos a un sitio web clonado de esta institución bancaria. El módem ha sido intervenido para que el dominio BBVA.MX sea “resuelto” en una IP distinta a la IP legal (23.3.212.126) para robar nuestros datos e información bancaria.
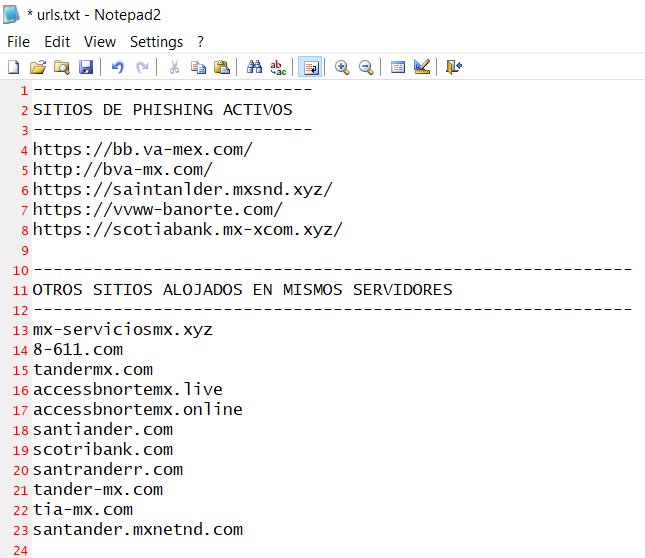
Como puedes observar en la captura de pantalla, los atacantes, han configurado la redirección de múltiples dominios de diversas instituciones bancarias para ser “resueltos” en servidores y dominios apócrifos, por ejemplo, aquí podrás ver una relación de sitios web de Phishing que he encontrado, y que están preparados para hacerse pasar por un banco y pedirte datos personales para robarte tu dinero:
¿Cómo te roban tus datos bancarios mediante técnicas de Phishing y vulnerabilidad en router Huawei HG8245H de TotalPlay?
Con la información que te he mostrado, y considerando un escenario en el que…
Tu router está intervenido y configurado con estos redireccionamientos.
Intentaste entrar a tu banco y te mostró el navegador una alerta a la cual, diste tu autorización de que “aceptas el riesgo” y;
Te encuentras en un sitio web clonado (Phishing) de la lista anterior (pero puede haber muchos otros eh)…
…los maleantes, han conseguido una primera fase de su objetivo: ganar tu confianza en su sitio web. ¿Qué ocurrirá a continuación?
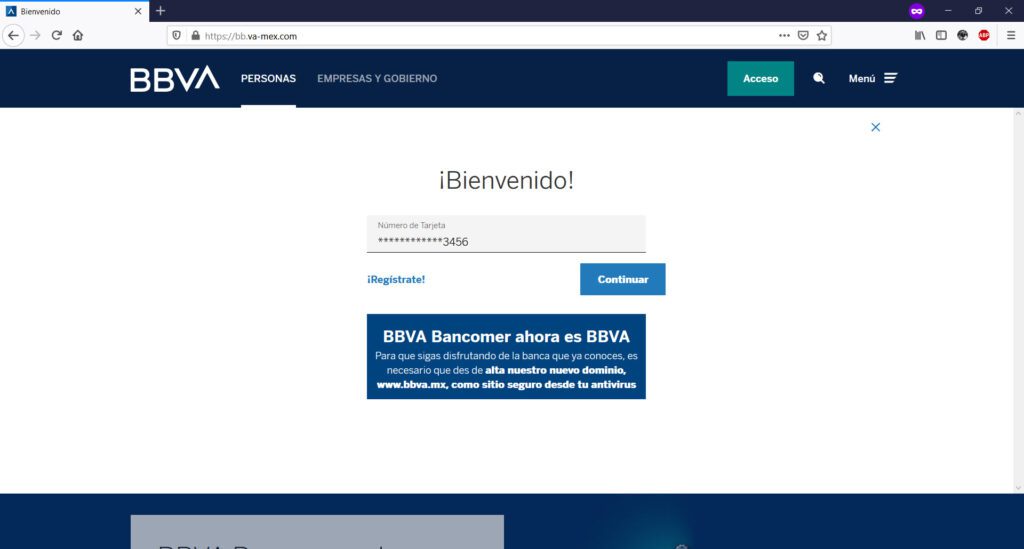
Básicamente, te encontrarás con algo como esto, siendo BBVA el caso de ejemplo de sitio web de phishing o clonado:
Te pedirán tu número de tarjeta de bancaria…
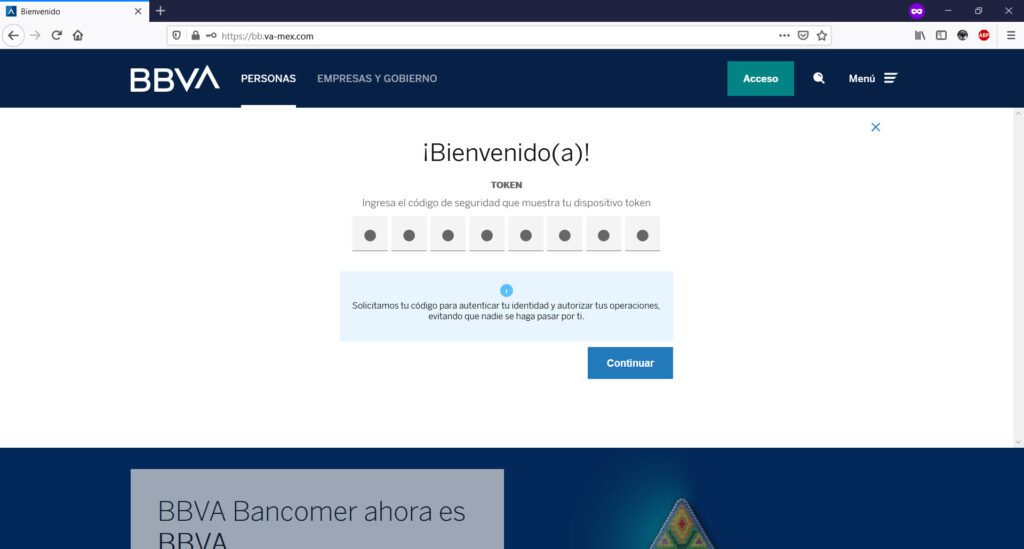
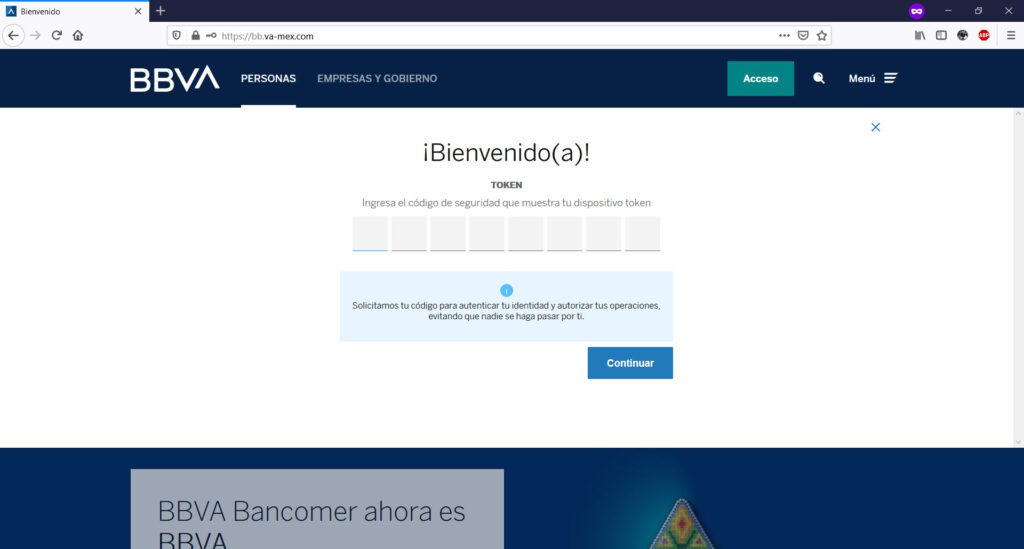
Te pedirán tu token de acceso (clave generada en tu app)…
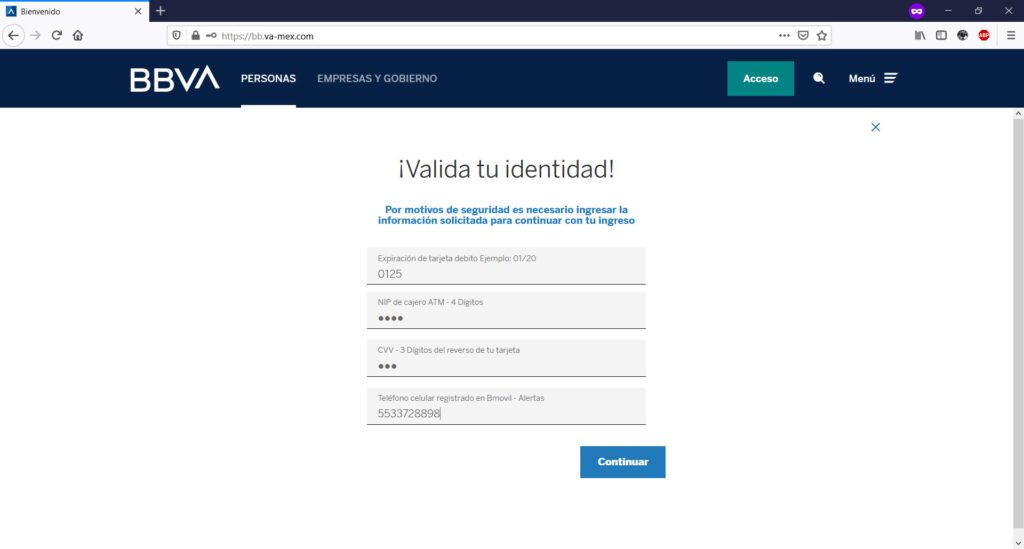
Hasta este punto, todo parecerá “normal” ya que son los datos básicos que generalmente una institución bancaria te pide para la banca en línea. Sin embargo, en las siguientes imágenes, los atacantes maliciosos te comenzarán a pedir información personal que a su vez, ellos podrán utilizar para ingresar a tu banca en línea y tomar el control de tu dinero:
Aquí, han creado un formulario en el cual te piden, “para validar”, datos de tu tarjeta bancaria y de registro de usuario.
Cuando “envías tus datos para validar”, sean estos válidos o inválidos, te aparecerá una leyenda de “Datos incorrectos”; el objetivo de esto, es el de “engancharte” con la realización de múltiples intentos para que consigas tu objetivo (entrar a tu banca en línea) pero, explotando esta necesidad tuya “proporcionándoles” el mayor número de tokens o confirmación de datos bancarios posibles (una vez que “diste tus datos bancarios”, entre más “tokens” proveas, es para ellos mejor) a través de su sitio web clonado o de phishing que para tal propósito han creado.
Aquí, te vuelven a pedir que ingreses tu token en un “nuevo intento” por haber ingresado “datos incorrectos” a “tu banco” (sitio web de phishing o clonado)… y así será sucesivamente hasta que te canses.
Un proceso similar al anterior ocurre con otros bancos, en los que realizan la clonación del mismo para implementar esos sitios web de phishing:
¿Cómo puedo protegerme del fraude bancario mediante esta técnica de phishing en router Huawei HG8245H de TotalPlay?
Tanto si eres usuario doméstico como administrador de red de una organización, lo principal es que:
1.- Resetees completeamente tu dispositivo a sus valores de fábrica y modifiques la contraseña de acceso del mismo, sobre todo si no puedes acceder a su panel de administración mediante la URL 192.168.100.1 con sus valores por defecto (usuario: root, pasword: admin) ya que, es muy probable que alguien te los haya cambiado.
Debes recordar que este router, solo permite cambiar contraseñas y no tiene forma de que se modifiquen sus nombres de usuario.
2.- Te asegures que tu dispositivo no tiene el puerto 23 abierto (si así te lo entregó el técnico de TotalPlay, me queda aún más la duda de si no es que hay personal dentro de la empresa entregando dispositivos configurados para ser vulnerados). Puedes realizar una prueba rápida así:
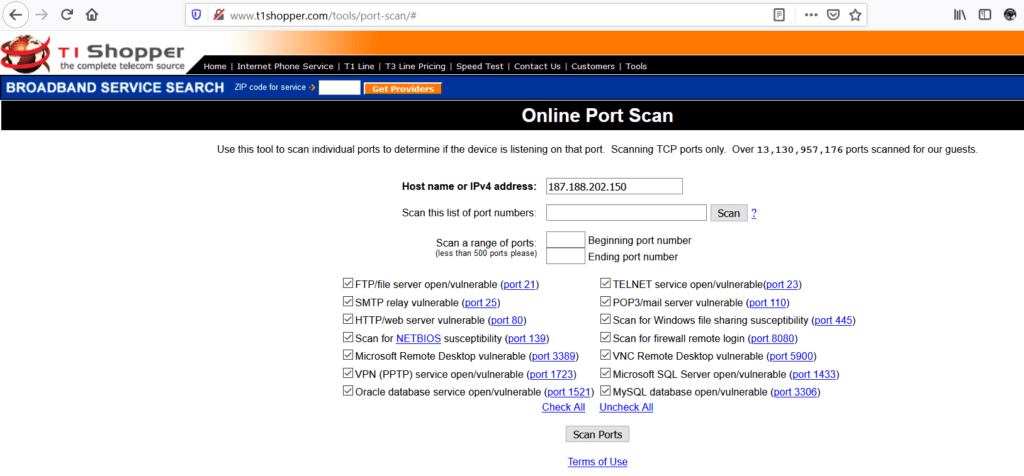
a) Investiga cuál es la IP pública de tu red; para ello, ingresa al sitio https://myip.es/, por ejemplo:
b) Una vez que tengas tu IP, ingresa a http://www.t1shopper.com/tools/port-scan/ y realicemos un escaneo rápido de puertos abiertos a tu dispositivo, no sin antes seleccionar “check all” para que se realicen pruebas en los puertos más comunes.
Si te aparece el puerto 23 abierto, es muy probable que tu dispositivo esté intervenido y vulnerable; en los resultados del escaneo, te estaría apareciendo algo así:
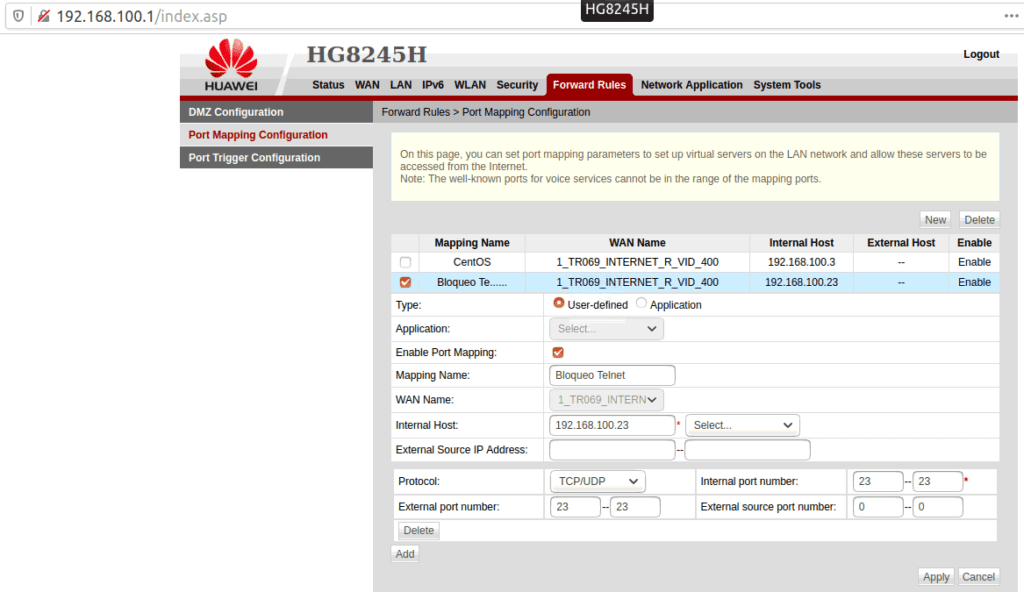
3.- Ya que tengas tu router Huawei HG8245H reseteado y con contraseña modificada, accede ahora al panel de control e ingresa al apartado “Forward Rules” y “Port Mapping Configuration”. A continuación crea una nueva regla (en “Mapping Name” ponle el nombre que desees) con los siguientes valores y haz clic en “Apply”:
Con lo anterior, ¡habrás aplicado una capa de seguridad a tu dispositivo para mitigar la vulnerabilidad en router Huawei HG8245H de TotalPlay.
Recomendaciones finales
Sin importar si eres un usuario doméstico o administrador de redes, espero que este artículo te haya servido.
En mi caso, una práctica que tengo por una Internet segura es el de notificar a ISPs, Google, Mozilla sobre la existencia de dominios con actividad maliciosa. No obstante, me he encontrado con la indiferencia de TotalPlay para resolver este tema (insisto nuevamente, me queda la impresión de que los “ataques” vienen de dentro de la red de ellos y no tanto de la red pública) así como también, el total desinterés de los bancos para responder a los llamados y dar protección a sus usuarios.
Por ello, te invito a que pongas atención en las siguientes recomendaciones.
Denuncia las URLs maliciosas siempre; en tu navegador Google Chrome haz clic en los “3 puntitos” de opciones adicionales, selecciona el menú “ayuda” y envía tu reporte con comentarios (importante que pongas “sitio de phishing”) haciend clic en “enviar reporte”; en el navegador Mozilla Firefox, haz clic en las “3 rayitas” de opciones adicionales, haz clic en el menú “ayuda” y envía también tu reporte haciendo clic en la opción “Reportar sitio fraudulento…”
Ten la buena práctica y costumbre de siempre verificar la validez de las URLs que visitas.
Enseña a tus usuarios y compañeros a navegar de manera segura.
Cambia tu router por otro mejor; los TP-Link Archer AX50, es un estupendísimo dispositivo que tiene una solución embebida para proteger a todos los usuarios de tu red de virus y bloquear URLs fraudulentas o de phishing. Si instalas Internet de TotalPlay, no te fíes de su router: compra y configúrate el Archer AX50 para que tengas mayor confianza y seguridad en tu red, sobre todo si vas a utilizar tu conexión para dar internet a tus empleados, cubrir tus oficinas, realizar tus operaciones bancarias, etc. Invierte en tecnología, en infraestructura, en asesoría de los expertos.
En mi oficina, tengo una vieja laptop a la cual, el monitor de cuando en cuando deja de funcionar sin forma de volver a encenderlo nuevamente. Con ello en consideración, decidí tomar esta laptop para configurarme un modesto servidor conUbuntu Server 14.04 LTS en el cual tengo habilitado Apache, PHP y MySQL principalmente con la cual te mostraré cómo conigurar una tarjeta de red con WPA desde la línea de comandos en Ubuntu.
Es pertinente comentar en este que punto que para el presente tutorial, procedí a realizar una instalación limpia de Ubuntu Server 14.04, configuré mi tarjeta de red, particiones y demás, pero al concluir el proceso de reinicio posterior a la instalación.
Así, para lograr que Ubuntu “inicie” y se “conecte” automáticamente a una red WPA, tenemos que seguir los siguientes pasos desde la consola o línea de comandos:
1.- Averiguamos en primer lugar el nombre de nuestra interface de red inalámbrica (generalmente es wlan0):
iwconfig
2.- Creamos el archivo de configuración del demonio de administración de redes wpa_supplicant…
sudo nano /etc/wpa_supplicant/wpa_supplicant.conf
…y guardamos dentro del mismo los siguientes valores:
5.- Pedimos ahora una dirección IP al servidor DHCP activo:
sudo dhclient wlan0
6.- Con ello, si hacemos un ping a google.com, deberías de obtener ya una respuesta. Pero bien, para que nuestra configuración se cargue en cada reinicio, abrimos el archivo /etc/network/interfaces…
sudo nano /etc/network/interfaces
…y nos aseguramos de añadir lo siguiente:
auto wlan0
iface wlan0 inet dhcp
wpa-ssid NOMBRE-DE-RED-WIFI
wpa-psk CONTRASEÑA-WIFI
7.- Para comprobar que el demonio wpa_supplicant se iniciará automáticamente en cada inicio del sistema, ejecutamos los siguientes comandos:
Un 16 de julio como hoy, pero del año 1969, en punto de las 12:32:00 hrs., dio inicio la misión definitiva que hizo posible la hazaña de posicionar al primer ser humano en la luna: la misión Apolo 11.
En este sentido, y teniendo en consideración que el 21 de julio de 1969 a las 2:56:00 hrs. (hora international UTC), el Instituto Smithsoniano, un centro de investigación y educación estadounidense que cuenta con una influyente red de museos, estará recordando y conmemorando este “pequeño salto para el hombre, pero un gigantesco salto para la humanidad” mediante el cual Neil Armstrong logró pisar por primera vez nuestro satélite, en compañía de Buzz Aldrin y Michael Collins.
Para ello, comparto en este espacio, una interesantísima infografía desde la cual podrás realizar un recorrido guía sobre la línea de tiempo en torno a los principales hitos que tuvo esta historia. Muy recomendable para recordar y conmemorar este singular evento.
Para todos aquellos que en algún momento tengan la necesidad de desarrollar actividades de administración de un servidor Web bajo GNU/Linux, descubrirán que Internet es un entorno más que propicio tanto para la colaboración o distribución de contenidos, como también, para prácticas maliciosas o ataques informáticos por lo que seguramente te resultará de gran utilidad el aprender a bloquear accesos por país con firewall CSF.
En este sentido, les comento que en mi práctica profesional, y concretamente, para el caso de una tienda en línea administrada con Magento, comencé a notar una baja en el performance impresionante, al punto tal en que las peticiones al servidor, se resolvían muy lentamente.
En este contexto, una solución “rápida” y “lógica” era incrementar los recursos del VPS contratado (más memoria RAM, más procesador), con el respectivo costo asociado.
Al revisar los logs de Apache (siempre es una buena práctica, algo tediosa) y las estadísticas del sitio en mi panel de control (con AW Stats o Webanalizer) y las visitas de Google Analytics, descubrí que tenía visitas en varias horas del día, y con distinta intensidad, del robot del buscador Chino llamado Baidu.
Con esta información en consideración, mi primer “movimiento” lógico, fue deshabilitar la indexación del agente/bot Baidu en el home de mi servidor, pero, el problema persistía: Baidu maneja diversos agentes (de contenidos, de imágenes, de video, etc.) para indexar un sitio, y para serles francos, aún y cuando Baidu tiene documentadas las medidas para el manejo de sus bots mediante el archivo robots.txt (puedes consultarlas aquí: http://help.baidu.com/question?prod_en=master&class=498&id=1000973), me dio la impresión de que sus bots no respetaban las instrucciones contenidas en el mismo, por lo cual, teniendo en consideración que el público de la tienda en línea era solo mexicano, procedí a realizar un bloqueo mediante reglas de un Firewall basado en software, inicialmente a China, con posibilidades de extenderlo a todo el mundo y permitir solo IP´s de México y Estados Unidos. Es importante destacar que Baidu, tiene una “página” en la cual uno puede “retroalimentar” y reportar incidentes; la liga es: http://webmaster.baidu.com/feedback/index. Aquí puedes encontrar más información sobre el “bloqueo” a Baidu Spider mediante el archivo robots.txt: http://www.baidu.com/search/robots_english.html
Consideraciones
Este “truco” te funcionará si tienes una distribución Linux en la cual tengas acceso como root o usuario con privilegios. Si tienes un VPS, asegúrate que si realizas por accidente un “bloqueo” a la IP desde la cual te conectas, podrás acceder nuevamente mediante una terminal o consola Web que te ofrezca tu propio proveedor.
Primeros pasos
CSF (ConfigServer Security & Firewall), es un poderoso conjunto de scripts que nos permiten disponer reglas de iptables para constituir un Firewall SPI (Stateful Packet Inspection) basado en software, con detector de intrusiones y seguridad en aplicaciones para servidores Linux.
Si actualmente tienes reglas de IPtables aplicadas en tu server, es muy probable que vayas a tener conflicto con las mismas, por lo cual, es muy probable que decidas qué solución de Firewall pretendes usar, o bien, analizar si CSF puede hacer por tí lo que actualmente estás haciendo con otra solución. Desde mi punto de vista personal, CSF es uno de los Firewalls para servidores Linux más potentes, transparentes y sencillos de usar que he visto.
Posteriormente, vamos a proceder a descargar y descomprimir el conjunto de scripts de CSF mediante el siguiente comando:
cd /usr/src
sudo wget https://download.configserver.com/csf.tgz
sudo tar -xzf csf.tgz
Ahora, procedemos a realizar la ejecución del script de instalación de CSF:
cd csf
sudo sh install.sh
Si no ha habido mayores problemas, podrás leer en tu pantalla algo como esto:
TCP ports currently listening for incoming connections:
22
UDP ports currently listening for incoming connections:
68,45861
Note: The port details above are for information only, csf hasn't been auto-configured.
Don't forget to:
1. Configure the following options in the csf configuration to suite your server: TCP_*, UDP_*
2. Restart csf and lfd
3. Set TESTING to 0 once you're happy with the firewall, lfd will not run until you do so
«lfd.sh» -> «/etc/init.d/lfd»
«csf.sh» -> «/etc/init.d/csf»
el modo de «/etc/init.d/lfd» permanece como 0755 (rwxr-xr-x)
el modo de «/etc/init.d/csf» permanece como 0755 (rwxr-xr-x)
Removing any system startup links for /etc/init.d/lfd ...
Removing any system startup links for /etc/init.d/csf ...
Adding system startup for /etc/init.d/lfd ...
/etc/rc0.d/K20lfd -> ../init.d/lfd
/etc/rc1.d/K20lfd -> ../init.d/lfd
/etc/rc6.d/K20lfd -> ../init.d/lfd
/etc/rc2.d/S80lfd -> ../init.d/lfd
/etc/rc3.d/S80lfd -> ../init.d/lfd
/etc/rc4.d/S80lfd -> ../init.d/lfd
/etc/rc5.d/S80lfd -> ../init.d/lfd
Adding system startup for /etc/init.d/csf ...
/etc/rc0.d/K80csf -> ../init.d/csf
/etc/rc1.d/K80csf -> ../init.d/csf
/etc/rc6.d/K80csf -> ../init.d/csf
/etc/rc2.d/S20csf -> ../init.d/csf
/etc/rc3.d/S20csf -> ../init.d/csf
/etc/rc4.d/S20csf -> ../init.d/csf
/etc/rc5.d/S20csf -> ../init.d/csf
«/etc/csf/csfwebmin.tgz» -> «/usr/local/csf/csfwebmin.tgz»
Installation Completed
Lo que debemos saber
CSF es una colección de scripts muy potente, que en un momento determinado, puede inclusive “impedirnos” la conexión remota al servidor si no tenemos muy claro lo que hacemos.
En este sentido, la ruta para la edición de su archivo de configuración, es:
/etc/csf/csf.conf
Dentro del mismo, tenemos 2 líneas que son muy interesantes:
TESTING = “1” – Si está activida esta regla así, es porque tu Firewall está en “modo de prueba” con lo cual, en función del valor asignado en el siguiente punto (testing_interval), pasado ese tiempo, te “borrará” todas las reglas de Firewall con el propósito de “regresar” a la normalidad. En otro caso, si has quedado conforme con la configuración de Firewall, puedes ponerle el valor de “0”, con lo cual, quedará aplicado este sistema.
TESTING_INTERVAL = “5” – Si las reglas de Firewall están en modo de prueba (testing), pasado número de minutos, se “limpiarán” del sistema, volviendo todo a la normalidad.
Bloquear accesos por país con firewall CSF y asignación de permisos de conexiones por país
Particularmente, CSF utiliza los 2 caracteres de país del código ISO de países CIDR (Classless Inter-Domain Routing – enrutamiento entre dominios sin clases) mediante el cual, se “clasifican” los rangos de direcciones IP de cada país. Como comenta CSF en el archivo de configuración, esta lista no es 100% segura ya que algunos ISPs, usan designaciones de IP para sus clientes mediante criterios no geográficos, lo cual dificulta su ubicación.
Por otra parte, la creación de reglas asociadas a grandes rangos de direcciones IP, pueden representar una disminución en el performance del servidor, con lo cual, no es muy recomendado para servidores VPS; aunque en mi caso, lo he usado en VPS de 1 GB de RAM y me fue muy bien, inclusive, me ayudó con tráfico indeseado.
Con ello en consideración, CSF se apoya en los 2 caracteres de país para la asignación en las reglas de Firewall, a partir de los bloques CIDR administrados por Maxmind GeoLite Country, el cual puedes consultar aquí: http://dev.maxmind.com/geoip/legacy/geolite/ (te sugerimos descargar el archivos CSV disponible para crear tus reglas con mayor seguridad y certeza).
Ahora bien, ¿qué haré? Permitiré el tráfico a México y Estados Unidos, y bloquearé al resto del mundo. Para ello, deberemos editar el archivo de configuración de CSF:
Ahora, guardamos el archivo, y reiniciamos el CSF:
sudo csf -r
Y revisamos las reglas aplicadas:
sudo iptables -L -n
Pasos finales
Por otra parte, con el objetivo de que nuestro Firewall tome acciones a partir de “falsos positivos” o “información confusa” proporcionada por los registros del sistema (syslog/rsyslog), en el archivo /etc/csf/csf.conf, debemos cambiar esto:
# 0 = Allow those options listed above to be used and configured
# 1 = Disable all the options listed above and prevent them from being used
# 2 = Disable only alerts about this feature and do nothing else
# 3 = Restrict syslog/rsyslog access to RESTRICT_SYSLOG_GROUP ** RECOMMENDED **
RESTRICT_SYSLOG = "0"
Por esto:
# 0 = Allow those options listed above to be used and configured
# 1 = Disable all the options listed above and prevent them from being used
# 2 = Disable only alerts about this feature and do nothing else
# 3 = Restrict syslog/rsyslog access to RESTRICT_SYSLOG_GROUP ** RECOMMENDED **
RESTRICT_SYSLOG = "3"
Con lo anterior, evitarás también “molestas” alertas del tipo:
*WARNING* RESTRICT_SYSLOG is disabled. See SECURITY WARNING in /etc/csf/csf.conf.
Goodie
CSF es un estupedísimo Firewal; para el caso de este material, podría decir que no está reservado solamente para “bloquear” rangos de IP´s de países sino para implementar un cortafuego por software a tu computadora o servidor.
Por ello, si modificas, en el siguiente conjunto de líneas, puede “decidir” qué puertos deseas mantener abiertos y en qué dirección:
…e inclusive, si permitirás que hagan “ping” a tu equipo:
# Allow incoming PING
ICMP_IN = "1"
Si has despertado la curiosidad con respecto a las capacidades de CSF, te recomendamos encarecidamente dar un vistazo a todo el fichero de configuración para hacer pruebas y descubrir sus posibilidades. ¡Te encantará! Cpanel lo integra generalmente a través de WHM, lo cual nos “garantiza” en cierto sentido su mejora y mantenimiento constante.
Nota final
Si al aplicar tus reglas de Firewall con CSF te aparece el mensaje de error:
*WARNING* URLGET set to use LWP but perl module is not installed, reverting to HTTP::Tiny
Es probable que te hayas olvidado de instalar paquetes de Perl de apoyo, con lo cual, solo hace falta instalar un módulo faltante mediante lo siguiente:
¿Qué pasa en este punto? Según comentan en algunos sitios, CSF implementó el procesamiento de peticiones para HTTP y HTTPS, con lo cual, el modelo LWP::UserAgent procesa muchísimo mejor HTTPS que el modelo HTTP::Tiny.
Si quisieramos evitar usar LWP, hay que buscar la línea:
En temas de seguridad y protección de servidores, no existe nada mejor que proteger los mismos con aplicaciones de detección de intrusiones como Snort (https://www.snort.org/) o Suricata (http://suricata-ids.org/) u otras ofertas comerciales basadas tanto en hardware (firewalls) como Software (http://www.acunetix.com/) o servicios en la nube (https://www.cloudflare.com/) que actualizan con mayor regularidad sus bibliotecas y/o diccionarios de ataques, y están “más preparados” ante estas amenazas de la red Internet, por los que reaizar análisis de logs de Apache con Scalp! es una fantástica idea para prevenir y/o anticipar amenazas.
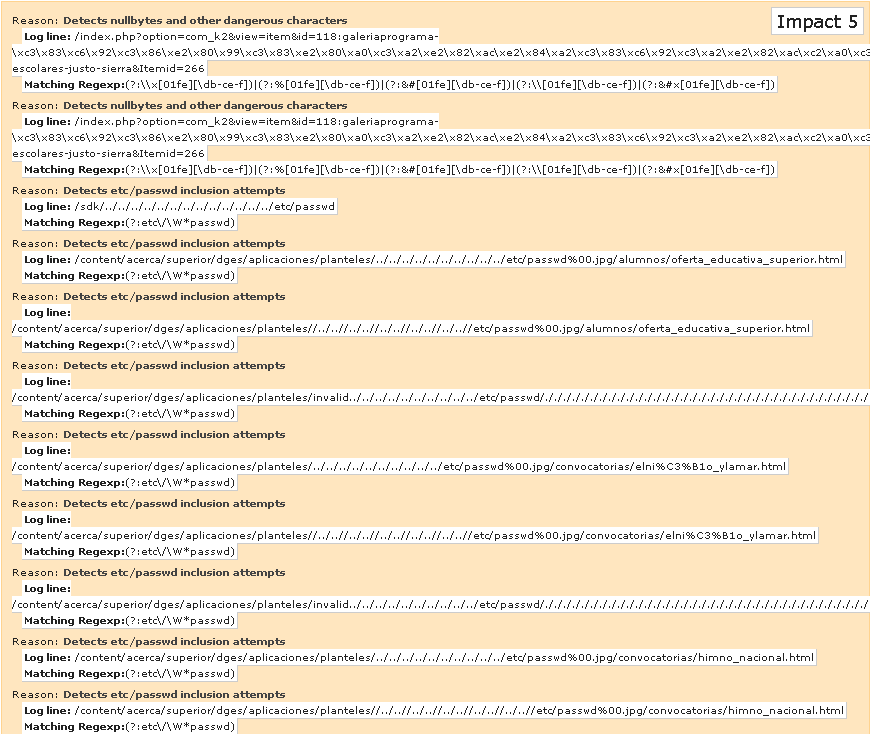
En esta ocasión les comparto un analizador de Logs muy sencillo, el cual propiamente, no es el más recomendado para “prevenir” ataques a un servidor Apache sino que más bien, su propósito es el de analizar potenciales huecos de seguridad o vulnerabilidades apoyándose de los registros (logs) que ha dejado atrás Apache para detectar aquellas áreas de oportunidad, mejora, e inclusive, vulnerabilidades propias de sistemas o aplicaciones desarrollados en PHP.
Scalp!, es un script analizador de logs del servidor Apache desarrollado en Phyton, que tiene como objetivo buscar problemas de seguridad. Su idea principal, es “leer” dentro de los registros de accesos al servidor para buscar patrones ataques potenciales mediante el envío de peticiones por los métodos HTTP/GET y HTTP/POST.
Para los propósitos de este post, he de comentar que estoy realizando pruebas sobre Ubuntu Server 14.04. En este caso, tengo una instalación con Apache 2, PHP5 y MySQL para un servidor Web, en donde mis “logs”, se encuentran dentro del directorio /var/logs/apache2/access.log.
Con esto en consideración, lo primero que tenemos que hacer, es “descargar” el script de Scalp! en nuestro directorio favorito:
(Nota: te sugiero que visites regularmente la página de Scalp! para descargar la última versión actualizada).
Ahora, descargamos el archivo de expresiones regulares que utiliza PHP-IDS (otra estupenda herramienta para proteger a nuestras aplicaciones PHP) para combinarlo en su uso con Scalp! mediante el siguiente comando:
En este caso, al ejecutar Scalp! por primera vez, me arrojó este mensaje de error:
The directory %s doesn't exist, scalp will try to create it
Loading XML file 'default_filter.xml'...
The rule '(?i:(\%SYSTEMROOT\%))' cannot be compiled properly
“Tuneando” nuestro fichero de patrones
Con respecto a la primera y segunda línea de error, no tenemos mayor problema. Más bien, el detalle que tenemos que resolver es que al parecer Phyton, no es capaz de “procesar” correctamente parte del contenido XML que descargamos de PHP-IDS. Para ello, la solución es muy sencilla, abrimos el archivo default_filter.xml con nuestro editor favorito:
A continuación, les aparecerá un mensaje como este, ante el cual, solo tenemos que esperar un poco (en función del tamaño de archivo de tu log o de las reglas que hayas pedido ejecutar):
Loading XML file 'default_filter.xml'...
Processing the file '/var/log/access.log'...
Scalp results:
Processed 491229 lines over 491413
Found 3175 attack patterns in 177.725208 s
Generating output in scalp-output/access.log_scalp_*
Ahora, solo tienes que ir al directorio scalp-output y “visualizar” en tu navegador en archivo generado para visualizar el reporte completo de patrones de ataque observados.
¡Esta herramienta es genial!
Goodie
Tecleando el comando:
python scalp-0.4.py --help
…podrás obtener la ayuda relacionada con otros patrones de uso de Scalp!.
Scalp the apache log! by Romain Gaucher - http://rgaucher.info
usage: ./scalp.py [--log|-l log_file] [--filters|-f filter_file] [--period time-frame] [OPTIONS] [--attack a1,a2,..,an]
[--sample|-s 4.2]
--log |-l: the apache log file './access_log' by default
--filters |-f: the filter file './default_filter.xml' by default
--exhaustive|-e: will report all type of attacks detected and not stop
at the first found
--tough |-u: try to decode the potential attack vectors (may increase
the examination time)
--period |-p: the period must be specified in the same format as in
the Apache logs using * as wild-card
ex: 04/Apr/2008:15:45;*/Mai/2008
if not specified at the end, the max or min are taken
--html |-h: generate an HTML output
--xml |-x: generate an XML output
--text |-t: generate a simple text output (default)
--except |-c: generate a file that contains the non examined logs due to the
main regular expression; ill-formed Apache log etc.
--attack |-a: specify the list of attacks to look for
list: xss, sqli, csrf, dos, dt, spam, id, ref, lfi
the list of attacks should not contains spaces and comma separated
ex: xss,sqli,lfi,ref
--output |-o: specifying the output directory; by default, scalp will try to write
in the same directory as the log file
--sample |-s: use a random sample of the lines, the number (float in [0,100]) is
the percentage, ex: --sample 0.1 for 1/1000
Si te interesa el tema, aquí puedes encontrar un estupendo artículo (en inglés) sobre una comparativa entre Snort y Suricata, los IDS (intrusion detection system) Open Source más populares. La liga es: http://wiki.aanval.com/wiki/Snort_vs_Suricata
ThingLink es una plataforma para la creación de gráficos interactivos, la cual está preparada para su integración en redes sociales. Particularmente, solo debemos cargar una imagen para comenzar a crear “etiquetas” las cuales, pueden contener texto, imagenes, video, audio y links, principalmente.
La versión gratuita es muy funcional; no obstante, la versión de paga te permite la integración y personalización de tus interacciones mediante el uso de otro tipo de recursos como iconos y analítica de datos.
Es una plataforma ideal para presentar tareas, productos, servicios, etc. ¡La imaginación es el límite!
Este año, Intel ha tenido la fantástica idea de lanzar un campaña publicitaria llamada “Sponsors of Tomorrow” que, para los que nos encontramos involucrados en la cultura hacker, explorando horizontes y buscando de soluciones tecnológicas simples para la vida cotidiana de las personas, nos permite dibujarnos una gran sonrisa, recordar quiénes somos e inspirarnos para ser mejores cada día. En el primer spot, con mucho humor Intel nos presenta a Ajay Bhatt, co-inventor del puerto USB (el estándar) como un rockstar de la ingeniería. Disfruta la lista completa de videos de la serie de Intel Sponsors of Tomorrow, ¡que la disfrutes!
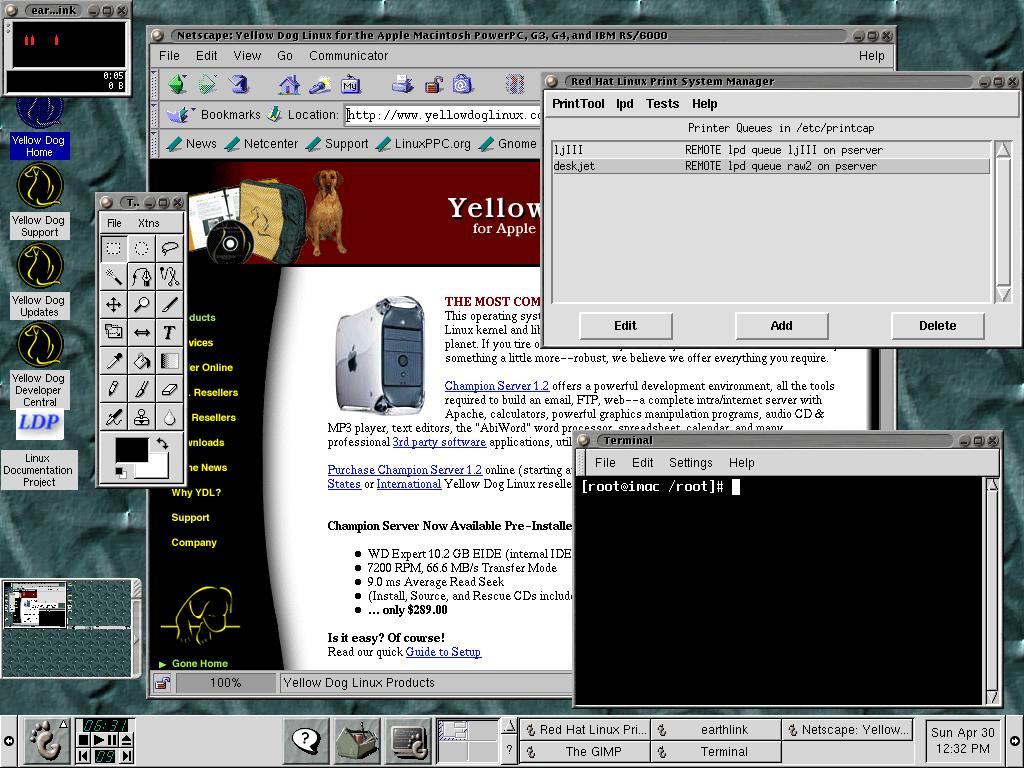
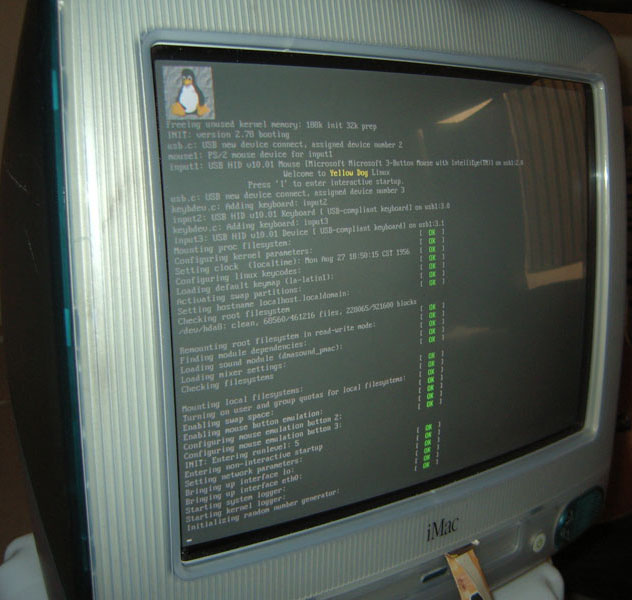
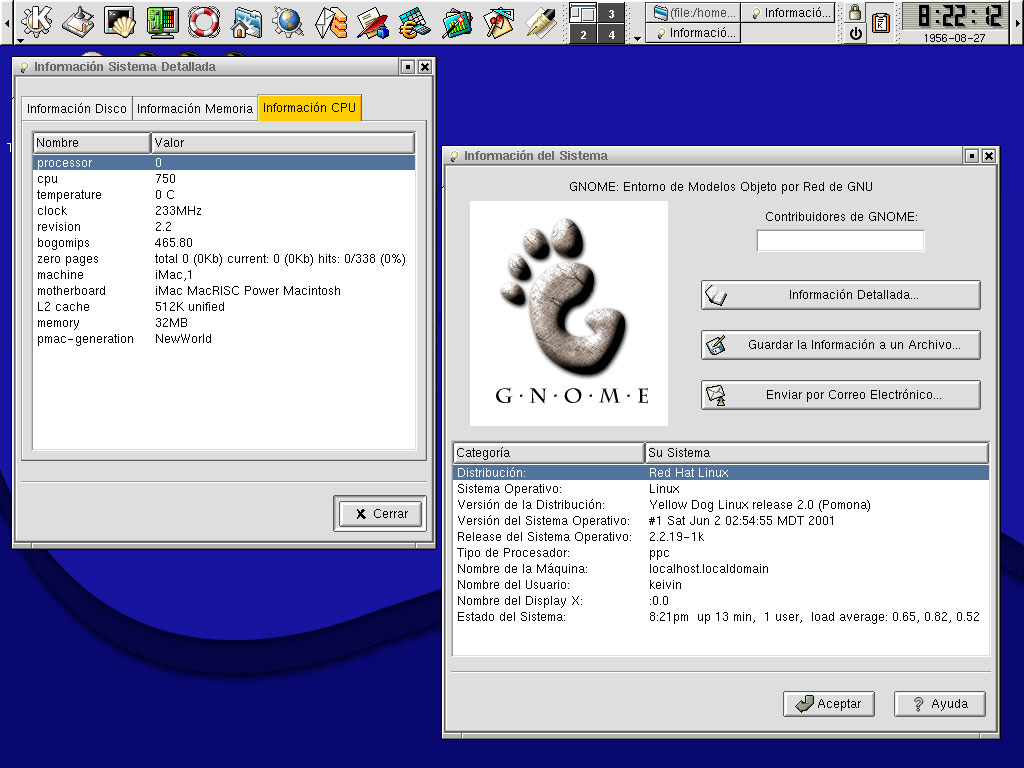
El día de hoy, recuperé una memoria USB en la cual tengo varios screenshots, documentos y curiosidades que vengo guardando de hace algunos años. Así pues, encontré algunas capturas de pantalla y fotografías de cuando, hace aproximadamente unos 5 años, instalé Yellow Dog Linux 2 Pomona en un iMac G3 a 233 mhz con 32 MB de memoria RAM. La verdad, KDE corría lentísimo, pero vale, queda para la historia, y como mera curiosidad: Linux funciona casi donde sea y con los recursos que sean.
Aquí, iniciando el sistema operativo…
Aquí, iniciando el escritorio KDE…
…y aquí puedes ver los recursos de la iMac G3 de mi distro Yellow Dog Linux para Mac.
Hago el Requiem por un desarrollador debido a que el día de ayer, se hizo eco en algunos blogs especializados y servicios de noticias, un ataque de día cero en contra de algunos proveedores de Hosting (y la triste historia de un desarrollador) que ofrecían servidores VPS (servidores privados virtuales dedicados) que utilizaban el panel de control LxAdmin e HyperVM para administrar planes con Xen y OpenVZ de la empresa hindú LxLabs.
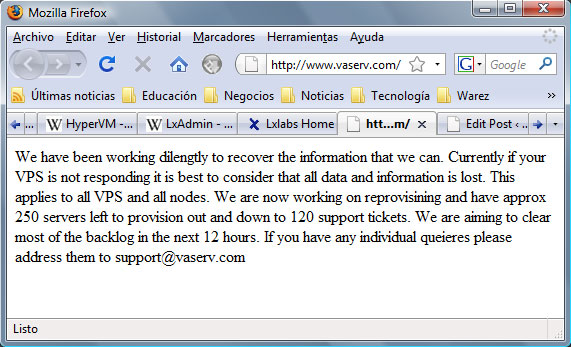
El resultado: más de 100,000 sitios web destruidos junto con sus respectivos backups. La empresa que más afectada se vio con esta situación, fue la Vaserv.com junto con sus compañías CheapVPS y FSCKVP.
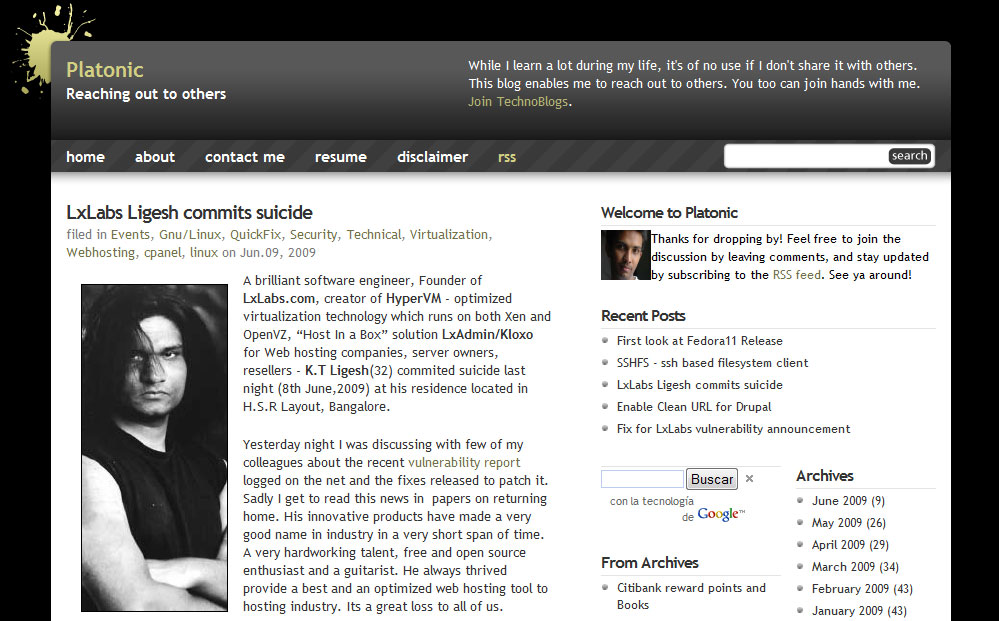
Por otra parte, se reportó que tan solo horas después del incidente, el genio desarrollador del entorno de administración de servidores VPS, creador y dueño de LxLabs, K.T. Ligesh se suicidó sin más, presumiblemente aquejado, por el desastre ocasionado, derivado de la vulnerabilidad usada en su aplicación.
En días anteriores, LxLabs había comentado que tenían reportes de contar con más de 30 000 servidores VPS en el mundo administrados con HyperVM, y más de 8 mil trabajando con Kloxo, otra plataforma de hosting de su creación. ¿Por qué era tan popular HyperVM? Sencillamente, por su extraordinario manejo de los recursos de memoria y procesamiento que permite que tan solo Kloxo, funcione sin problema alguno con 15 MB de memoria. En verdad, ésta compañía ofrecía un sistema de administración de servidores a un muy pero muy bajo costo, comparado con los precios de un servidor dedicado.
Caramba, la verdad, ufff, poco se puede hacer en situaciones así; sucesos que en verdad, están más allá de nuestro alcance, aún y cuando mediante algunas prácticas, es posible reforzar la seguridad hasta cierto punto. Hay quienes comentan que los respaldos, se creaban en el mismo servidor en el cual se configuraban las máquinas virtuales, lo cual hizo que al momento, poco se pueda hacer para restaurar los datos.
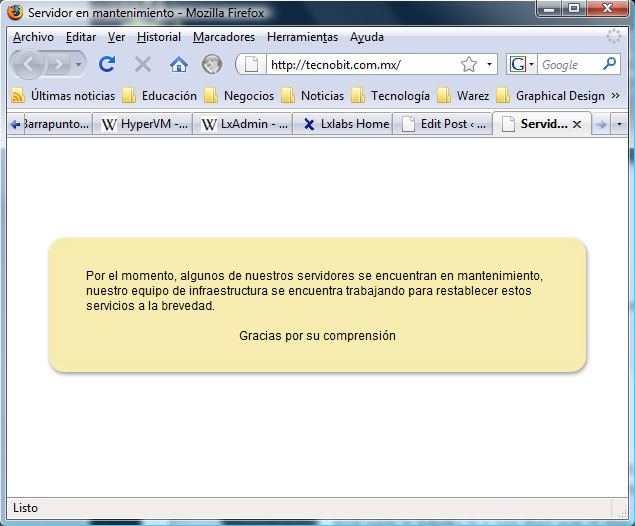
Según tengo entendido, algo similar ocurrió en México a la empresa TecnoBit.com.mx, quienes a ésta hora, continúan caídos e intentando recuperar sus datos. No estoy muy seguro de si haya sido en realidad un ataque y/o cómo haya sido. Lo que sin duda alguna queda, es el sabor amargo de los terroristas digitales. Al día de hoy, ya existe en Internet un reporte completo sobre el exploit en el cual se basaron para realizar el ataque.

 Generalmente, uno accede a las propiedades del mouse de la computadora para realizar configuraciones adicionales del dispositivo.
Generalmente, uno accede a las propiedades del mouse de la computadora para realizar configuraciones adicionales del dispositivo.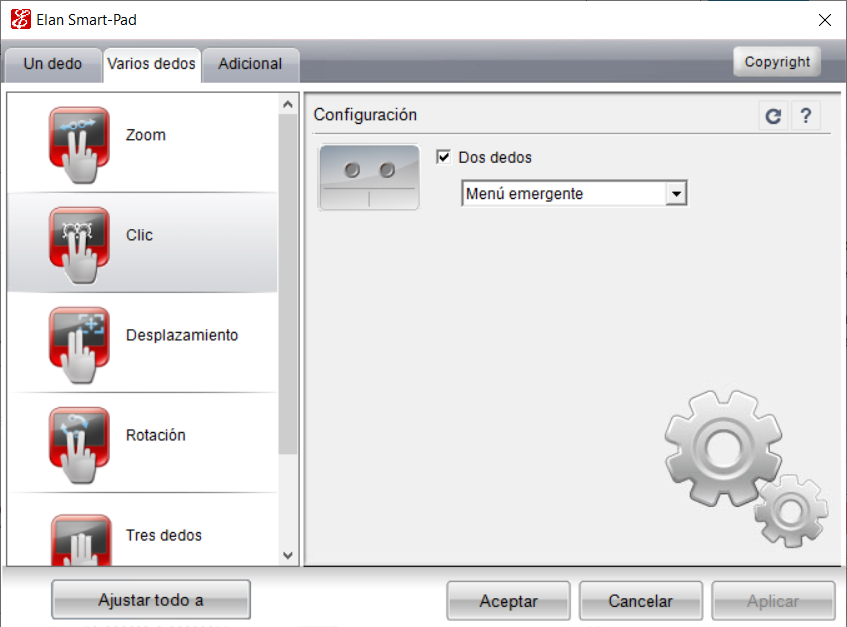















Debe estar conectado para enviar un comentario.